NLP任务的难点
不像图像的普适性, 语言本身有其多样性, 如语境的偏移, 背景的变化, 人与人间的分歧, 这导致以下问题:
- 有标注数据的通用性低
- 标注数据质量不稳定
- 现实世界的语言和使用场景不断更新, 导致模型的维护更新换代成本极高
- …
为了应对NLP的难点, 需要充分利用各种可用的监督信号,包括但不限于传统监督学习(supervision),自监督学习(self-supervised),弱监督(weak supervision),迁移学习(transfer learning),多任务学习(multi-task learning, MTL)。
Near-term improvements in NLP will be mostly about making clever use of “free” data.
语言模型 - 经典的自监督学习模型
Lecun有给自监督学习下定义,但我个人对自监督的理解是,基于数据本身进行学习,让模型学习到数据隐含的特征。
比如语言模型的根据前文预测下一个单词。
最近的BERT丰富了玩法,提出了Mask language model,就是通过上下文预测掩码位置的单词,作为其核心学习任务;BERT的训练过程还应用了多任务学习,把 next sentence prediction 也作为任务之一一起学习。
目前除了语言模型和句模型(next sentence),是否还有其他任务?
Baidu ERNIE: 引入了论坛对话类数据,利用 DLM(Dialogue Language Model)建模 Query-Response 对话结构,将对话 Pair 对作为输入,引入 Dialogue Embedding 标识对话的角色,利用 Dialogue Response Loss 学习对话的隐式关系。
ELMo vs GPT vs BERT
经典Word2vec表达是context free的,open a bank account和on the river bank的bank共用一个向量值[0.3, 0.2, -0.8, …]. 如指公司的苹果和指水果的苹果共用一个向量.
解决方案:在文本语料中训练上下文表达contextual representations
而 ELMo, GPT, 和 BERT 都着眼于contextual representations
- ELMo : Deep Contextual Word Embeddings, 训练独立的
left-to-right和right-to-left的LMs, 外加一个Word Embedding层, 作为预训练的词向量使用 - OpenAI GPT : Improving Language Understanding by Generative Pre-Training. 使用
left-to-rightTransformer LM, 然后在下游任务中fine-tune - BERT : Bidirectional Encoder Representations from Transformers

但是, 为何2018年之前类似ELMo的contextual representations并不流行?
因为好的预训练结果比有监督训练代价高1000倍甚至100,000倍。2013年微调好的二层512维度的LSTM sentiment analysis 有 80% 准确度, 训练时间 8 小时. 同期的相同结构的预训练模型需要训练一周, 准确率稍微好点, 80.5%.
迁移学习的两种思路: Feature based 和 Fine-tune based
ELMO区分不同同词不同意的方法是通过它的三层向量的加权组合(concat or sum whatever), 权重可以在下游任务中学习调整.
而GPT和BERT是通过在下游任务中fine-tune模型参数, 同时也利用了transformer的self-attention机制解决共指消解 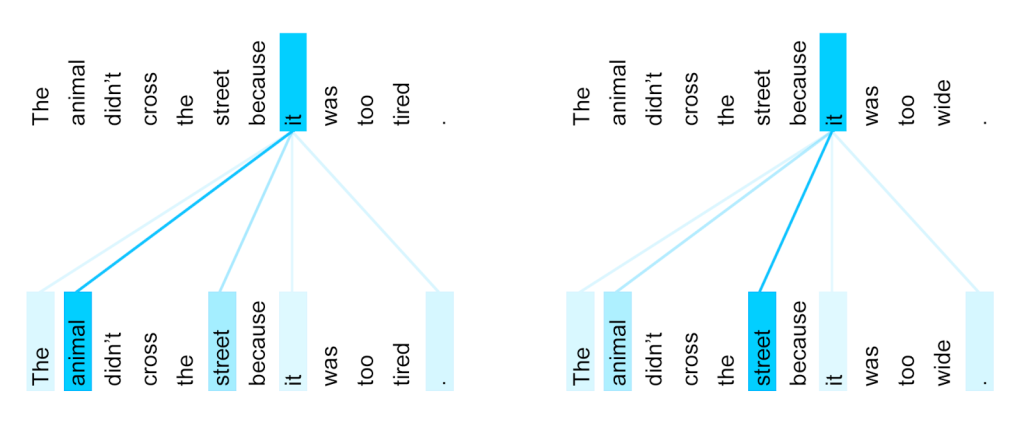
而这三个模型是一个不断进化的过程:
- ELMO 独立地训练前后向LSTM, 每一个位置只能直接接收其左右相邻位置的信息, 而且因为实践上LSTM cell 能够记忆的距离很有限(能够记忆的信息也很有限), 这导致ELMO的全局语境理解能力很有限.
- GPT 是从左到右
- BERT 放弃了"预测下一个词"的传统LM任务, 改用Mask-LM任务.
BERT模型学习的应该不仅仅是contextual embeddings:
预测缺失的单词(或下一个单词)需要学习许多类型的语义理解features: 语法,语义,语用,共指等.
这说明预训练模型其实远远大于它所需要解决的任何特定下游任务
迁移学习
迁移学习的主流思路是知识共享, 让模型在一种较为通用的数据上预训练, 然后把预训练的模型迁移到下游的具体任务中.
迁移学习在图像领域大获成功(ImageNet + resnet),解决了分类这一图像领域的瓶颈。
近年来涌现出ULMFit, ELMO,GPT, BERT这些优秀的预训练模型,但没有CV领域那么耀眼。主要原因是NLP目前没有单个明确的瓶颈,
- NLP需要多种多样的推理:逻辑,语言语义,情感,和视觉。
- NLP要求长期短期结合的记忆
比较综合的语言理解任务是GLUE。
BERT,GPT-2 等算法指明了一条可行的 NLP 在实际工业应用的可行路径:
- 预训练:利用超大规模无监督数据预训练神经网络模型
- (可选) 知识注入, 加入知识图谱的结构化信息, 如基于BERT的ERNIE
- 知识迁移,二个思路:
- 微调 Fine-tune
- 单任务/多任务学习
预训练
预训练阶段的核心是什么?
resnet,BERT和GPT-2告诉我们: 更大的数据规模,更多样性的数据,更高的数据质量。这三点的尺度上限都接近无穷大,所以天花板很高,未来模型的性能还有提升空间。- 针对数据量大和多样性,我们有两种解决思路,
- 预训练阶段需要自监督或者无监督的任务,显而易见的任务是语言模型, ELMo, GPT, 和 BERT 都用到了这个任务.
- 使用弱监督(远程监督)
知识注入
百度的ERNIE的做法是: 基于百度的词库, 把BERT中对token level 的 mask 改进为 对 word level 的 mask.
- 对于每一个序列, 我们需要进行 word level 的标记, 来区分各个 token 是否属于同一个词.
- 对序列进行掩码时, 不再是随机选择 token, 而是选择词
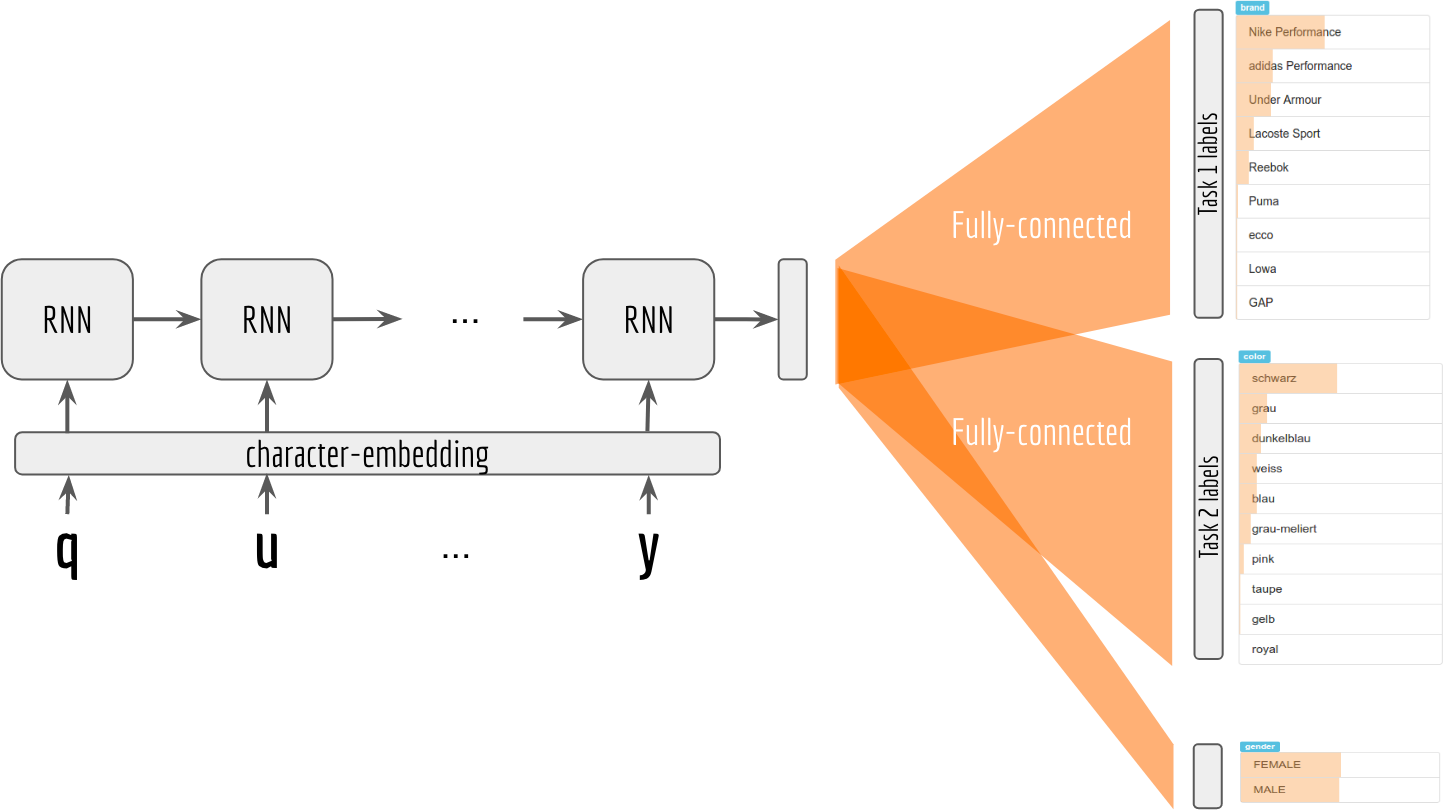
多任务学习
与单独训练模型相比,多任务学习在使用shared representation的同时并行地学习任务。通过shared representation在任务之间传递知识,可以提高特定任务模型的学习效率和预测准确性。
有两种MT思路:
- Hard parameter sharing:不同任务共享底层的神经网络层,但各个任务有自己特定任务的output layer。同时学习的任务越多,模型底层就越能找到捕捉所有任务的表达,而对单个任务过度拟合的可能性就越小。
- Soft parameter sharing:每个任务有自己的模型自己的参数,然后对各个模型的参数之间的距离进行正则化,以鼓励参数趋近。
Hard parameter sharing的训练,目前至少有两种方式。
- 交替地优化每个任务特定的
task_loss[k]. 这种方法不需要各个任务的训练数据有任何对齐关联 - 联合优化
total_loss=Σ(task_loss[k])。 这个方法要求各个任务的batch训练数据相同或者有key来对齐
除此之外, 第二种方法还方便我们为每个任务添加自适应权重(adaptive weight),以获得更多task-sensitive learning。
{kind=link}
弱(远程)监督
Snorkel MeTaL
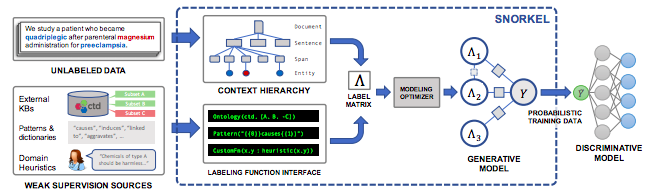
- Hard-coded heuristics: usually regular expressions (regexes)
- Syntactics: for instance, Spacy’s dependency trees
- Distant supervision: external knowledge bases
- Noisy manual labels: crowdsourcing
- External models: other models with useful signals
Reference
- Building NLP Classifiers Cheaply With Transfer Learning and Weak Supervision
- Snorkel DryBell: A Case Study in Deploying Weak Supervision at Industrial Scale
- Data Programming: Creating Large Training Sets, Quickly
- Improving Language Understanding by Generative Pre-Training
- https://github.com/kweonwooj/papers/issues/114
- Massive Multi-Task Learning with Snorkel MeTaL: Bringing More Supervision to Bear
- An Overview of Multi-Task Learning in Deep Neural Networks
- Training Complex Models with Multi-Task Weak Supervision
- https://nlp.stanford.edu/seminar/details/jdevlin.pdf
- Get 10x Speedup in Tensorflow Multi-Task Learning using Python Multiprocessing