知识图谱补全
基于知识表示的方法
知识表示学习:对知识图谱中的实体和关系学习其低维度的嵌入式表示。
常见的知识表示学习方法:主要是以 TransE 法及其变种为核心,针对空间映射等场景做的改进
基于实体和关系的表示对缺失三元组进行预测;
利用实体描述信息,可以解决开放域实体补全的问题;
基于路径查找的方法
可使用基于路径查找的方法来处理这类多步推理问题。
传统的路径查找方法主要是 PRA 方法(Path Ranking Algorithm);但是这种方法对于包含较大规模的知识图谱来说,会由于路径数量爆炸式增长,导致特征空间急剧膨胀
可以尝试用 embedding 的方式表示关系,对关系进行泛化,并基于此对知识的补全进行建模,以缓解路径数量过多导致的特征空间膨胀问题。
- 给定实体对集合,利用 PRA 查找一定数量的路径;
- 路径计算过程中加入实体类型信息(减少长尾实体影响);
- 使用 RNN 沿着路径进行向量化建模;RNN 模型参数在不同关系之间共享;
- 通过比较路径向量与待预测关系向量间的关联度来进行关系补全。
基于强化学习的方法
前面提到的两种方法,仍然存在若干的问题:
- 需要基于 random walk 来查找路径;
- 而 random walk 算法在离散空间中运行,难以评价知识图谱中相似的实体和关系;
- 超级结点可能影响 random walk 算法运行速度。
强化学习方法:
- 在连续空间中进行路径搜索;
- 通过引入多种奖励函数,使得路径查找更加灵活、可控。
DeepPath
DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning
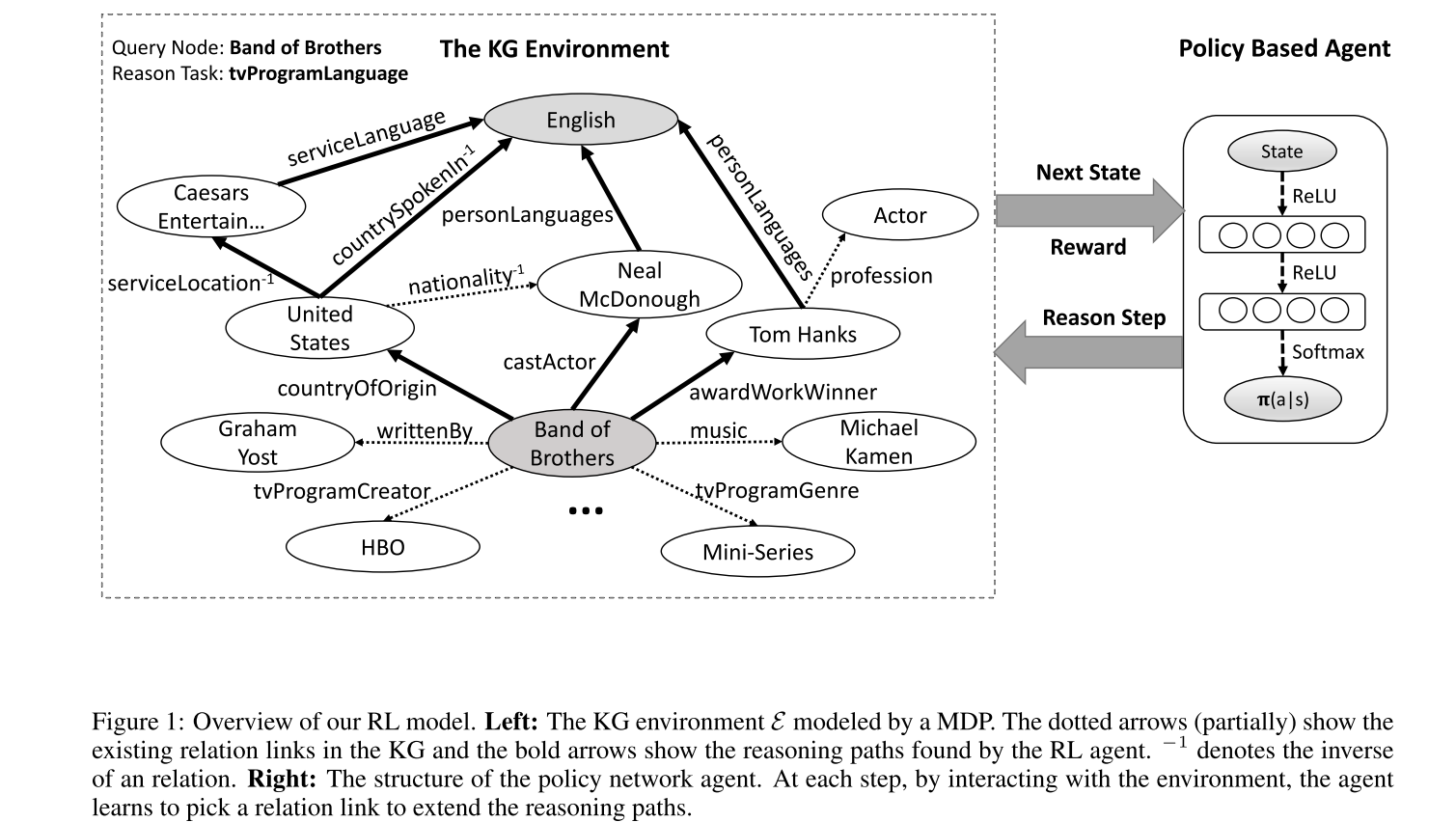
- 任务:查找 Band of Brothers 和 English 之间的关系。
- 路径起点:Band of Brothers
- 状态:实体中的 embedding
- 动作:图谱中的关系;
- 奖励
- Binary,是否到达终点
- 路径长度
- 路径多样性
- 策略网络:使用全连接网络。
DeepPath 方法仍然存在一些缺陷:知识图谱本身的不完善很可能对路径查找造成影响。
Collaborative Policy Learning for Open Knowledge Graph Reasoning
在路径查找过程中,通过抽取关系,将缺失的路径补全。