Cong Chen
University of Edinburgh
InstructGPT1, ChatGPT2, and GPT-43 are cutting-edge Large Language Models (LLMs) that have astounded the world. With their ability to follow human instructions and align with human preferences, they can act as chatbots or helpful assistants. Despite impressing people for a while, their development lifecycles have not yet been thoroughly elaborated.
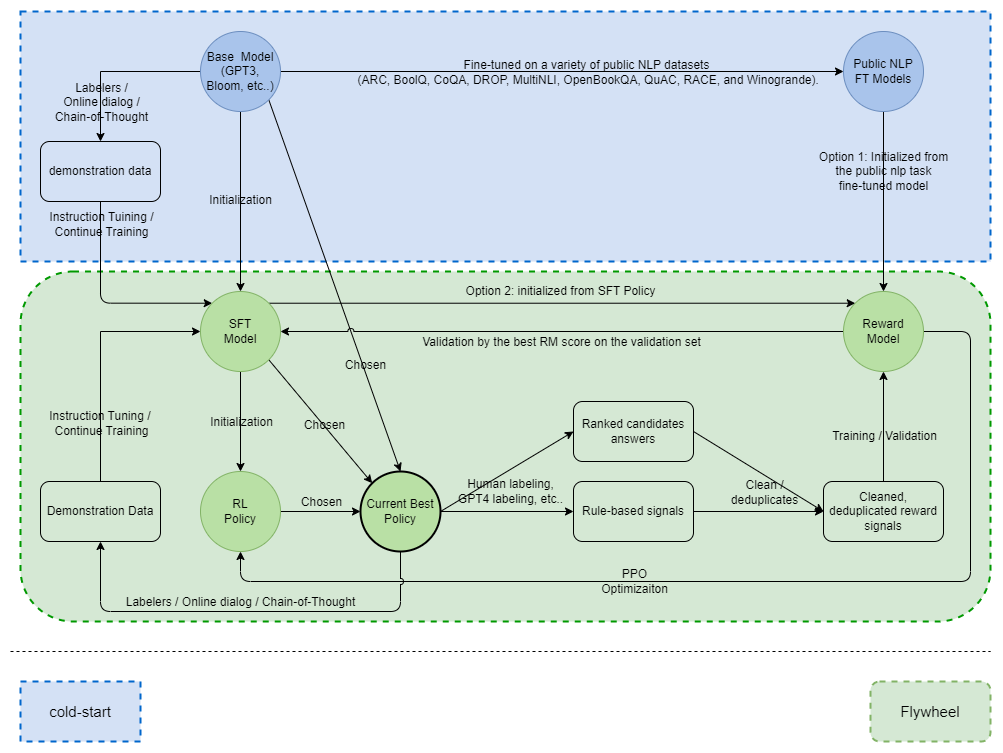
In this blog, I will provide my observations and thoughts based on my recent experience with large language model training and alignment. Instead of introducing these LLMs and highlighting their impressive performance, I will focus on the bootstrap flywheel that continuously improving these models. The bootstrap flywheel is showed in below graph with further illustration in this post.
Cold Starts
To kickstart the process, it is essential to obtain a pre-trained LLM. One option is to pre-train an LLM from scratch. An alternative approach is to use a pre-trained LLM that has already undergone extensive training on diverse sets of text data. Open-source pre-trained LLMs, such as LLaMA4,5 and BLOOM6,7, have gained a comprehensive understanding of word associations and contextual nuances. Due to their expertise, these models are already capable of generating natural-sounding text.
Instruction-tuning on Demonstration Data
We begin with an alpha model, which is a pre-trained LLM. To develop the initial instruct-following GPT model, we have two options: (1) ask labelers to create prompts and responses on their own, or (2) collect online conversations as demonstration data. We feed the prompts or dialogue context and train the model to produce responses as training targets. This process is commonly known as instruction-tuning, or supervised fine-tuned(SFT).
Nowadays, the ChatGPT/GPT4 API is frequently utilized to extract high-quality demonstration data at a remarkably low cost, utilizing Chain-of-Thought(CoT)8 and self-instruction9 approach.
With proper instruction-tuning, many open-sourced pre-trained LLMs can become quite effective at following human instructions. To utilize the model, users simply input a prompt or message, and the model continuously predicts the most probable next word or phrase based on its pre-existing knowledge. This streamlined approach enables swift and precise language generation for a wide range of applications.
The outcomes are truly thrilling! We got a highly refined instruction-tuned LLM model that required minimal training effort. We are absolutely thrilled about the endless possibilities that this approach presents and are eagerly anticipating the release of our ChatGPT, hoping to capture the attention of many users. But soon we found that to reach a higher level, we need to put in much more effort.
Alignment
While the SFT model delivers impressive results, it is prone to some challenging issues. For example, it can generate hallucinations10,11, falls into traps or gives inappropriate or even dangerous suggestions. Therefore, to ensure the model works effectively with a broad range of users and environments, it must meet a high standard of compliance. This means it shouldn’t only follow instructions but also communicate in a way that aligns with most people’s preferences. These cases occur frequently and demonstrate that the model requires further refinement before it can be made available for public use.
Learning from Human Feedback
OpenAI’s solution to further optimize a LLM is to utilize Reinforcement Learning from Human Feedback (RLHF)12. This technique is a form of reinforcement learning (RL) that leverages human feedback to optimize an agent, using methods such as proximal policy optimization (PPO)13. This feedback loop helps the agent learn from experience and adjust its behavior, making it a useful approach in cases where optimal behavior is difficult to define.
To make RLHF works, we need a very good LLM policy as a starting point. The SFT model can serve as this initial policy, and different models trained at different stages can be used, as checkpoints are saved periodically during training. OpenAI selects the best policy by using a reward model (RM) which helps choose the best SFT model based on its RM score on a validation set. This approach has been found to produce more accurate predictions of human preference results than simply using validation loss.
However, RLHF does not represent the sole viable approach. Some promising non-RL methods have been thoroughly investigated. For instance, the MOSS14 team has directly utilized the output of the reward model as fine-tuning signals. Non-RL methods are often more attractive due to their ease of training.
Reward Model
A reward model can serve as an environment evaluator to replace human effort. Specifically, for a given prompt and answer, the reward model can evaluate the quality of the answer in relation to the prompt. The output of the reward model is a simple scalar value.
To collect reward training data, we can sample different answers from various pre-trained or SFT models for each prompt as input. This process is repeated with different prompts. For each prompt with several responses, human labelers rank these responses according to pre-defined guidelines. The end result is a collection of examples, where each example consists of a unique prompt with several ranked responses.
The training process involves a simple ranking supervised learning approach to optimize a reward model. There is not much difference in whether the reward model is initialized from a pre-trained model such as GPT-3 or SFT models, and OpenAI has tried both with similar results. In the InstructGPT paper, they initialized a reward model from a 6B GPT-3 model that was fine-tuned on a large set of public NLP tasks (ARC, BoolQ, CoQA, DROP, MultiNLI, OpenBookQA, QuAC, RACE, and Winogrande). This is a clever idea for cold-starts.
With a reasonably good reward model, we can optimize a policy, initialized from an SFT model, using RLHF or other reward model guided methods. The well-optimized policy model, which is the best we have so far, is then ready to interact with various users and environments.
The Bootstrap Flywheel
In conclusion, after cold starts, we can iteratively upgrade our LLM with a bootstrap flywheel driven by data.
- A better SFT model helps to generate more representative responses for ranking.
- The better the ranking data can represent human preferences, the stronger the reward model can be trained.
- The more powerful the reward model is, the more promising the policy we can have.
This iterative process allows us to continuously improve our LLM and create more effective and efficient conversational agents. Each sub-process could introduce new information, but also noises. Hence careful data-engineering is always required.
Ouyang, Long, et al. Training Language Models to Follow Instructions with Human Feedback. arXiv:2203.02155, arXiv, 4 Mar. 2022. arXiv.org, http://arxiv.org/abs/2203.02155. ↩︎
Touvron, Hugo, et al. LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971, arXiv, 27 Feb. 2023. arXiv.org, http://arxiv.org/abs/2302.13971. ↩︎
https://ai.facebook.com/blog/large-language-model-llama-meta-ai/ ↩︎
BigScience, BigScience Language Open-science Open-access Multilingual (BLOOM) Language Model. International, May 2021-May 2022 ↩︎
Wei, Jason, et al. Chain of Thought Prompting Elicits Reasoning in Large Language Models. arXiv:2201.11903, arXiv, 10 Oct. 2022. arXiv.org, http://arxiv.org/abs/2201.11903. ↩︎
Wang, Yizhong, et al. Self-Instruct: Aligning Language Model with Self Generated Instructions. arXiv:2212.10560, arXiv, 20 Dec. 2022. arXiv.org, http://arxiv.org/abs/2212.10560. ↩︎
John Schulman - Reinforcement Learning from Human Feedback: Progress and Challenges ↩︎
Yoav Goldberg, April 2023. Reinforcement Learning for Language Models ↩︎
Stiennon, Nisan, et al. Learning to Summarize from Human Feedback. arXiv:2009.01325, arXiv, 15 Feb. 2022. arXiv.org, http://arxiv.org/abs/2009.01325. ↩︎
Schulman, John, et al. Proximal Policy Optimization Algorithms. arXiv:1707.06347, arXiv, 28 Aug. 2017. arXiv.org, http://arxiv.org/abs/1707.06347. ↩︎