Codex:M. Chen et al., ‘Evaluating Large Language Models Trained on Code’. arXiv, Jul. 14, 2021. Available: http://arxiv.org/abs/2107.03374
Intro
Codex, a GPT language model finetuned on publicly available code from GitHub
Task: docstring-conditional code generation
Method
Codex: fine-tune GPT3 models containing up to 12B parameters on code to produce Codex.
Codex-S: fine-tune Codex on standalone, correctly implemented functions.
Inference: assemble each HumanEval problem into a prompt consisting of a header, a signature, and a docstring. We use nucleus sampling (Holtzman et al., 2020) with top p = 0.95 for all sampling evaluation in this work
Codex-D: generate docstrings from code, for safety reasons, as such a model can be used to describe the intent behind generated code
效果/Analysis/Findings
Evaluation Framework:pass@k, a sample is considered correct if it passes a set of unit tests.
Benchmark: HumanEval, a new evaluation, measure functional correctness for synthesizing programs from docstrings, with a set of 164 handwritten programming problems
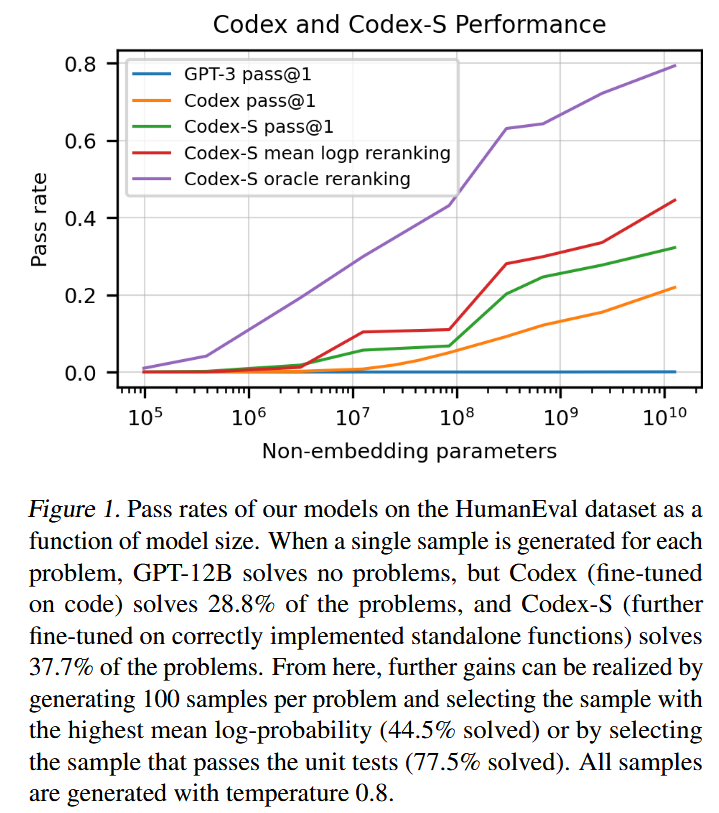
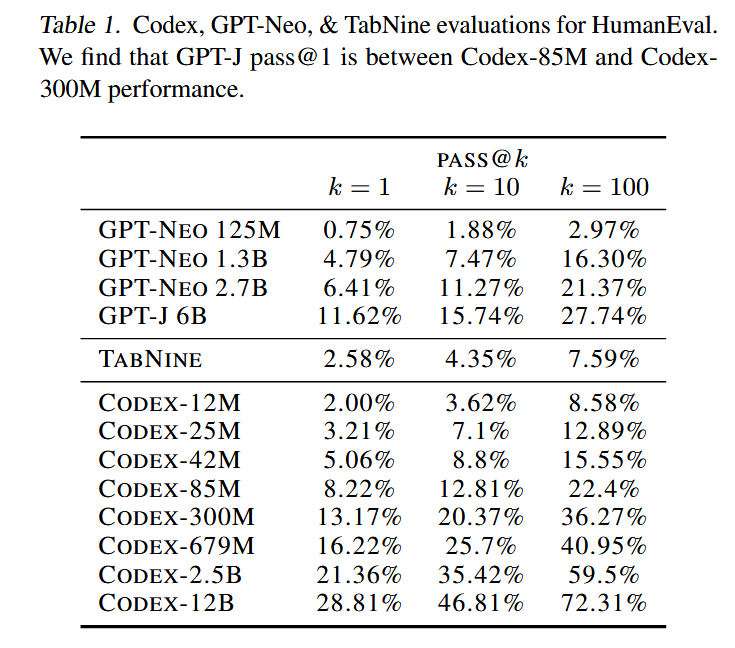
- Codex solves 28.8% of the problems, while GPT-3 solves 0% and GPT-J solves 11.4%
- Codex solve 70.2% of our problems with 100 samples per problem
BLEU score may not be a reliable indicator of functional correctness by showing that functionally inequivalent programs generated by our model often have higher BLEU scores than functionally equivalent ones.
limitations
- difficulty with docstrings describing long chains of operations and with binding operations to variables.
- Codex is not sample efficient to train
- Codex can recommend syntactically incorrect or undefined code, and can invoke functions, variables, and attributes that are undefined or outside the scope of the codebase
Application
- A distinct production version of Codex powers GitHub Copilot
- education, safety, security, and economics
Additional Reading
- GPT-J: Wang, B. and Komatsuzaki, A. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. https://github.com/ kingoflolz/mesh-transformer-jax, May 2021. GPT-J 6B is a transformer model trained using Ben Wang’s Mesh Transformer JAX. GPT-J 6B was trained on the Pile, a large-scale curated dataset created by EleutherAI.
- Rotary Position Embedding (RoPE)
- GPT-Neo
- APPS dataset: a benchmark for code generation, measures the ability of models to take an arbitrary natural language specification and generate satisfactory Python code, includes 10,000 problems,
- Nucleus Sampling, a simple but effective method to draw the best out of neural generation. By sampling text from the dynamic nucleus of the probability distribution, which allows for diversity while effectively truncating the less reliable tail of the distribution, the resulting text better demonstrates the quality of human text, yielding enhanced diversity without sacrificing fluency and coherence.