2020, ACL
data: CoNLL-2012, GAP
task: Coreference Resolution
通过QA方式处理coreference问题,A query is generated for each candidate mention using its surrounding con- text, and a span prediction module is em- ployed to extract the text spans of the corefer- ences within the document using the generated query.
近期的方法有consider all text spans in a document as potential mentions and learn to find an antecedent for each possible mention. There。这种仅依靠mention的做对比的方法的缺点:
- At the task formalization level: 因为当前数据集有很多遗漏的mention, mentions left out at the mention proposal stage can never be recov- ered since the downstream module only operates on the proposed mentions.
- At the algorithm level:Semantic matching operations be- tween two mentions (and their contexts) are per- formed only at the output layer and are relatively superficial
方法
Speaker information: directly concatenates the speaker’s name with the corresponding utterance.

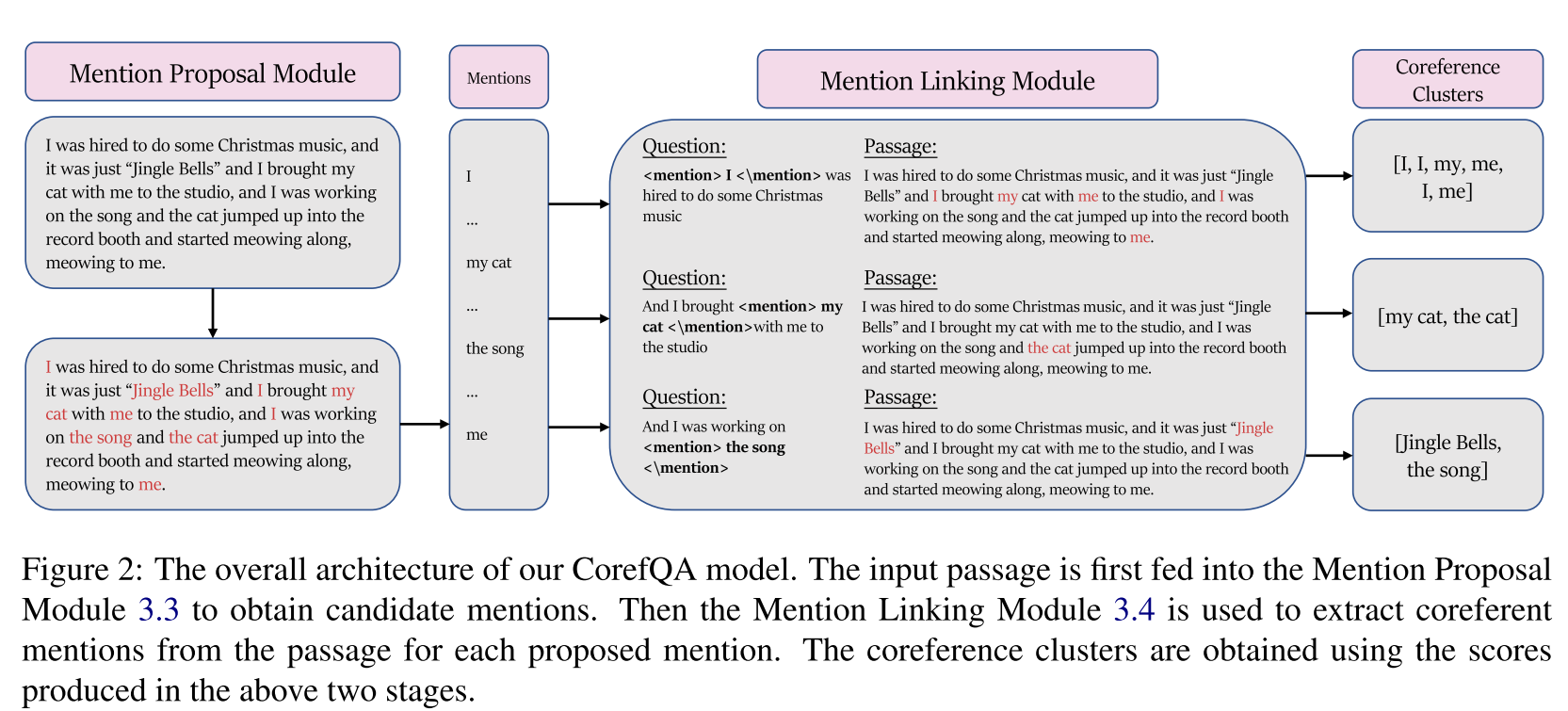
3.3 Mention Proposal
considers all spans up to a maximum length L as potential mentions.
3.4 Mention Linking as Span Prediction
Given a mention ei proposed by the mention pro- posal network
{context (X), query (q), answers (a)}.
The query q(ei) is constructed as follows: given ei, we use the sentence that ei resides in as the query, with the minor modification that we encapsulates ei with special tokens < mention > < /mention >
generate a BIO tag for each token of a coreferent mention

to optimize the bi-directional re- lation between ei and ej.


3.5 Antecedent Pruning
Training
The mention proposal module and the mention linking module are jointly trained in an end-to-end fashion using training signals from Eq.6, with the SpanBERT parameters shared.
3.8 Data Augmentation using Question Answering Datasets
pre- train the mention linking network on the Quoref dataset (Dasigi et al., 2019b), and the SQuAD dataset (Rajpurkar et al., 2016b)
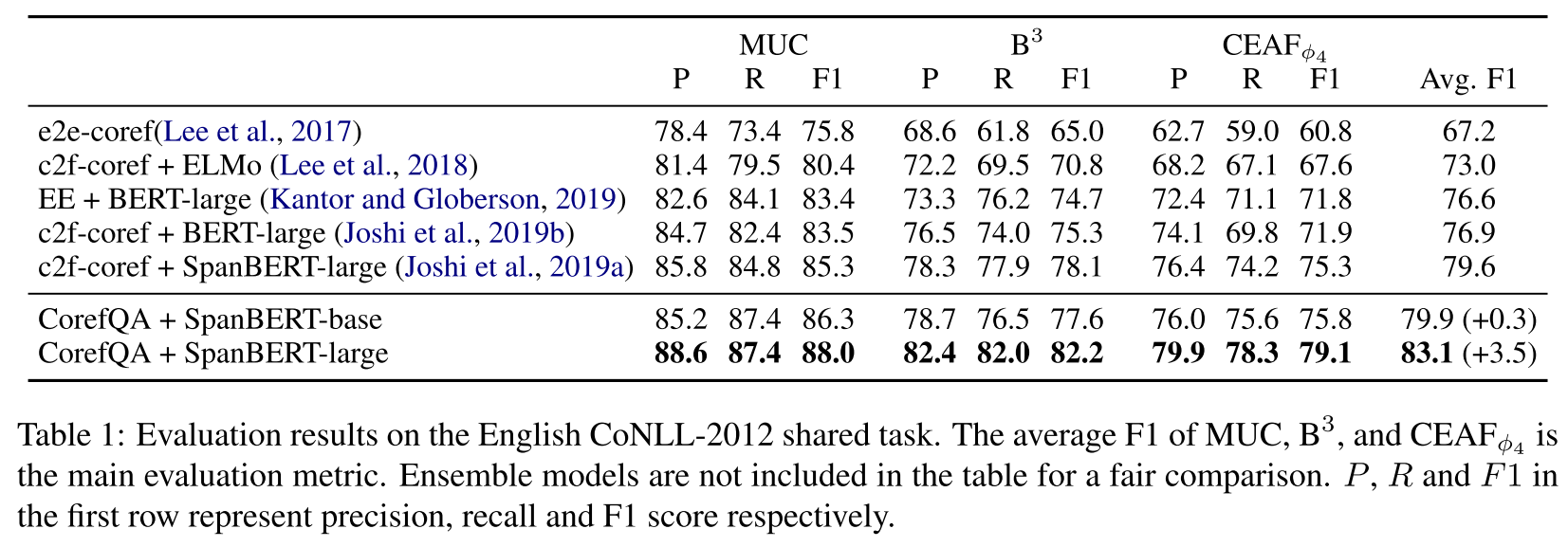
效果