CoT on BBH:M. Suzgun et al., ‘Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them’. arXiv, Oct. 17, 2022. Available: http://arxiv.org/abs/2210.09261
Method
Applying chain-of-thought (CoT) prompting to BIG-Bench Hard tasks
Evaluate few-shot performance via standard “answer-only” prompting and chain-of-thought prompting on BIG-Bench Hard Benchmark
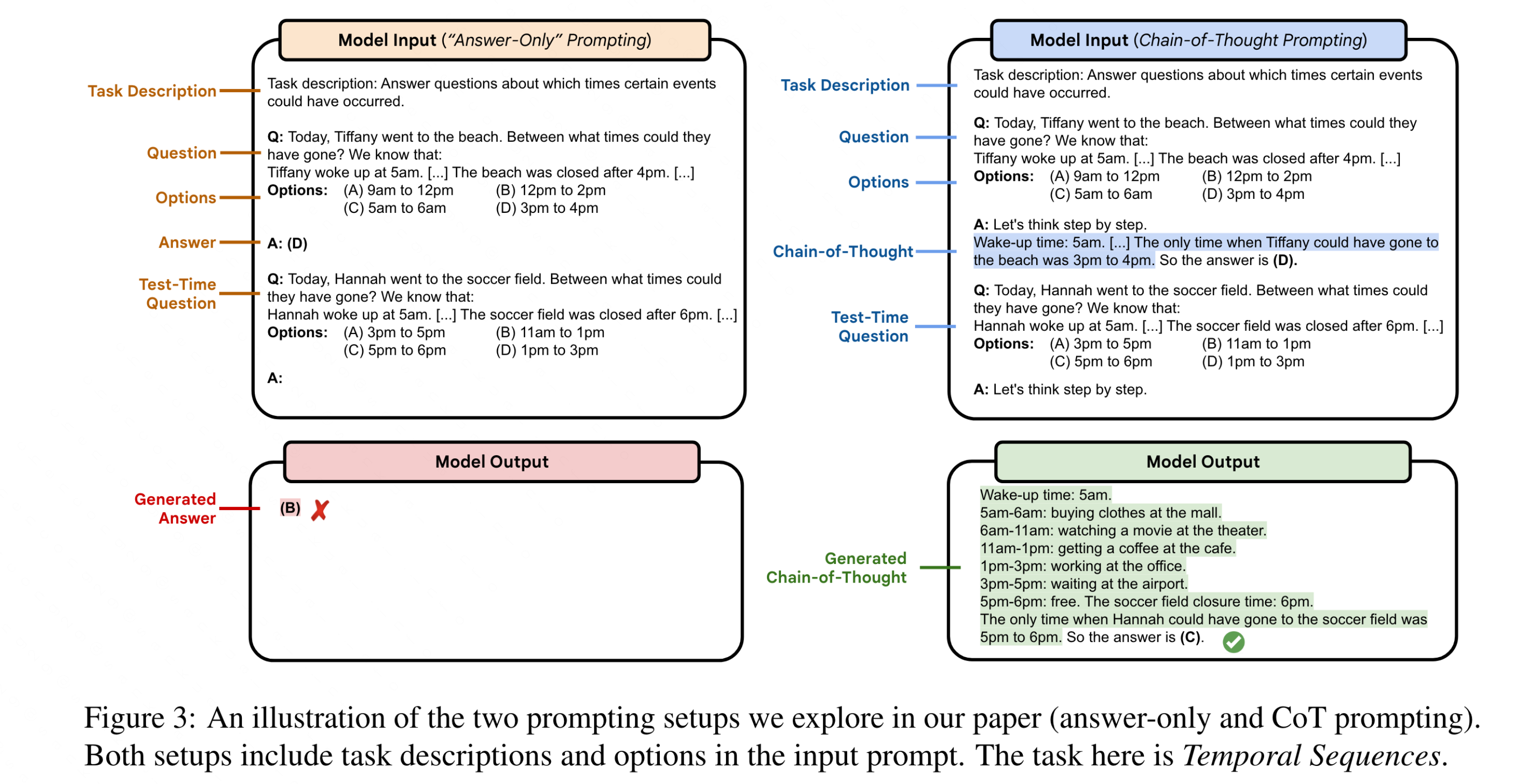
Results/Analysis/Findings
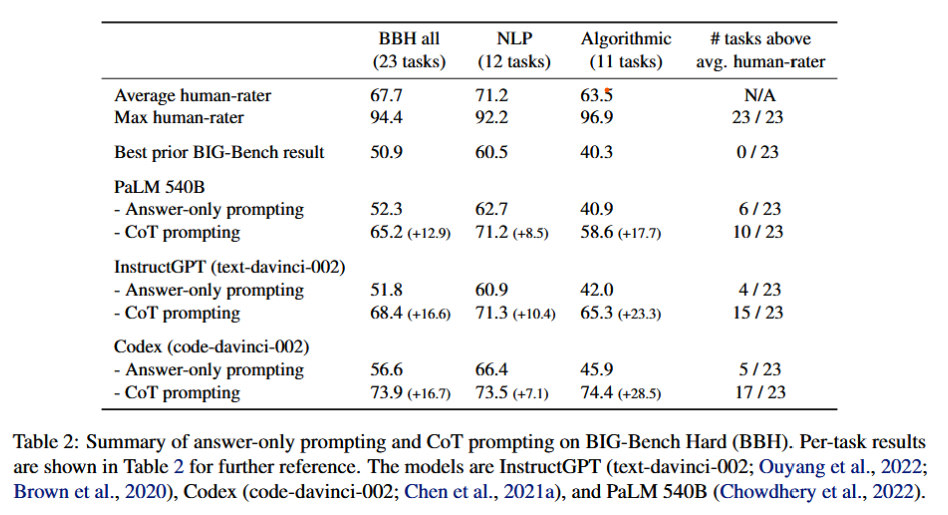
Benchmark: BIG-Bench Hard (BBH). These are the task for which prior language model evaluations did not outperform the average human-rater. many tasks in BBH require multi-step reasoning
Consider three families of language models: Codex (codedavinci-002, code-davinci-002, code-cushman-001), InstructGPT (text-davinci-002, text-curie-002, text-babbgage-001, and text-ada-001), and PaLM (8B, 62B, and 540B).
效果: CoT prompting provides double-digit improvements for all three models. Applying chain-of-thought (CoT) prompting to BBH tasks enables PaLM to surpass the average humanrater performance on 10 of the 23 tasks, and Codex (code-davinci-002) to surpass the average human-rater performance on 17 of the 23 tasks
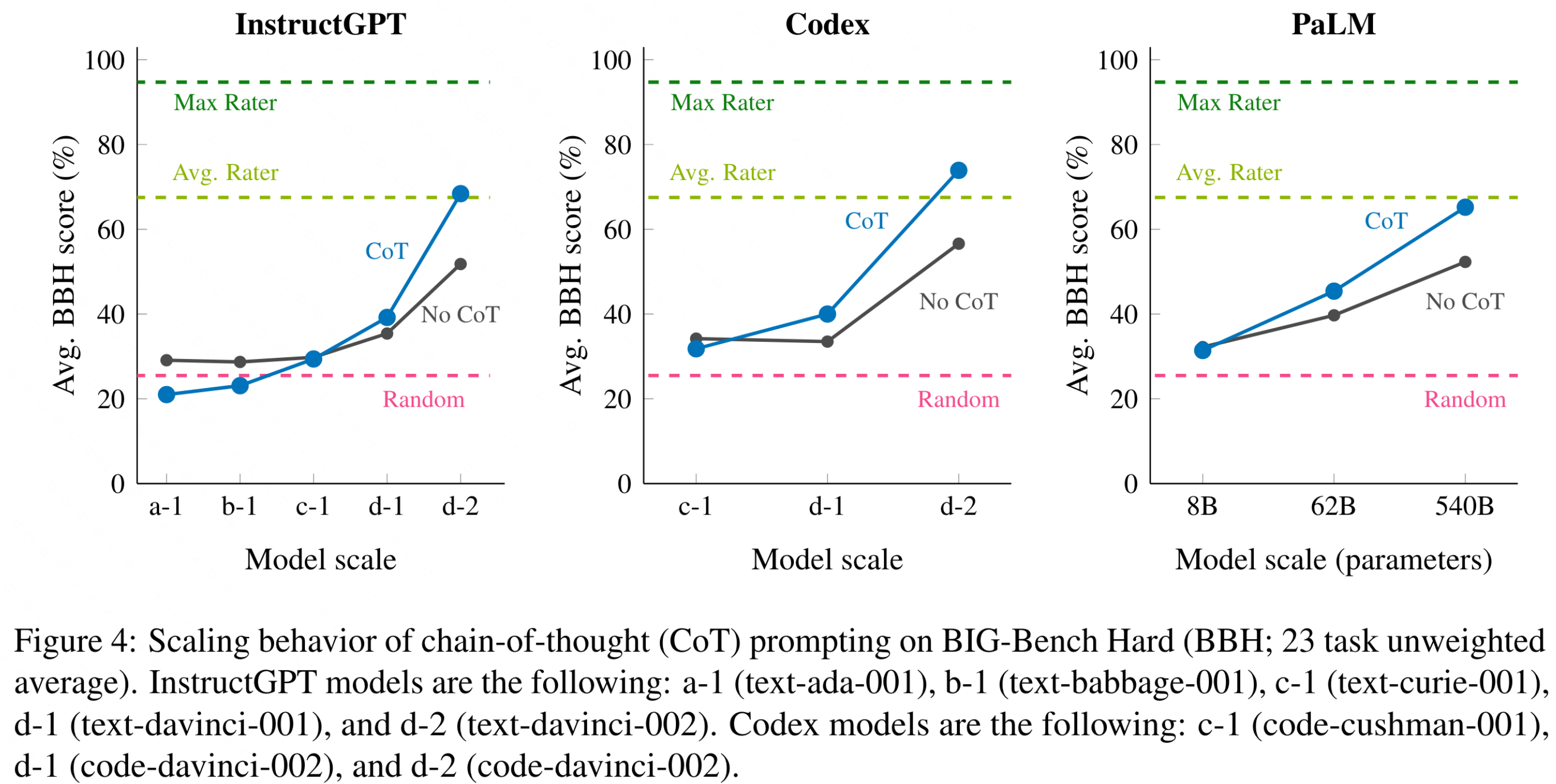
CoT is an emergent prompting strategy (Wei et al., 2022a) that requires sufficiently large models.: CoT prompting has negative or zero performance gain for the smallest model size
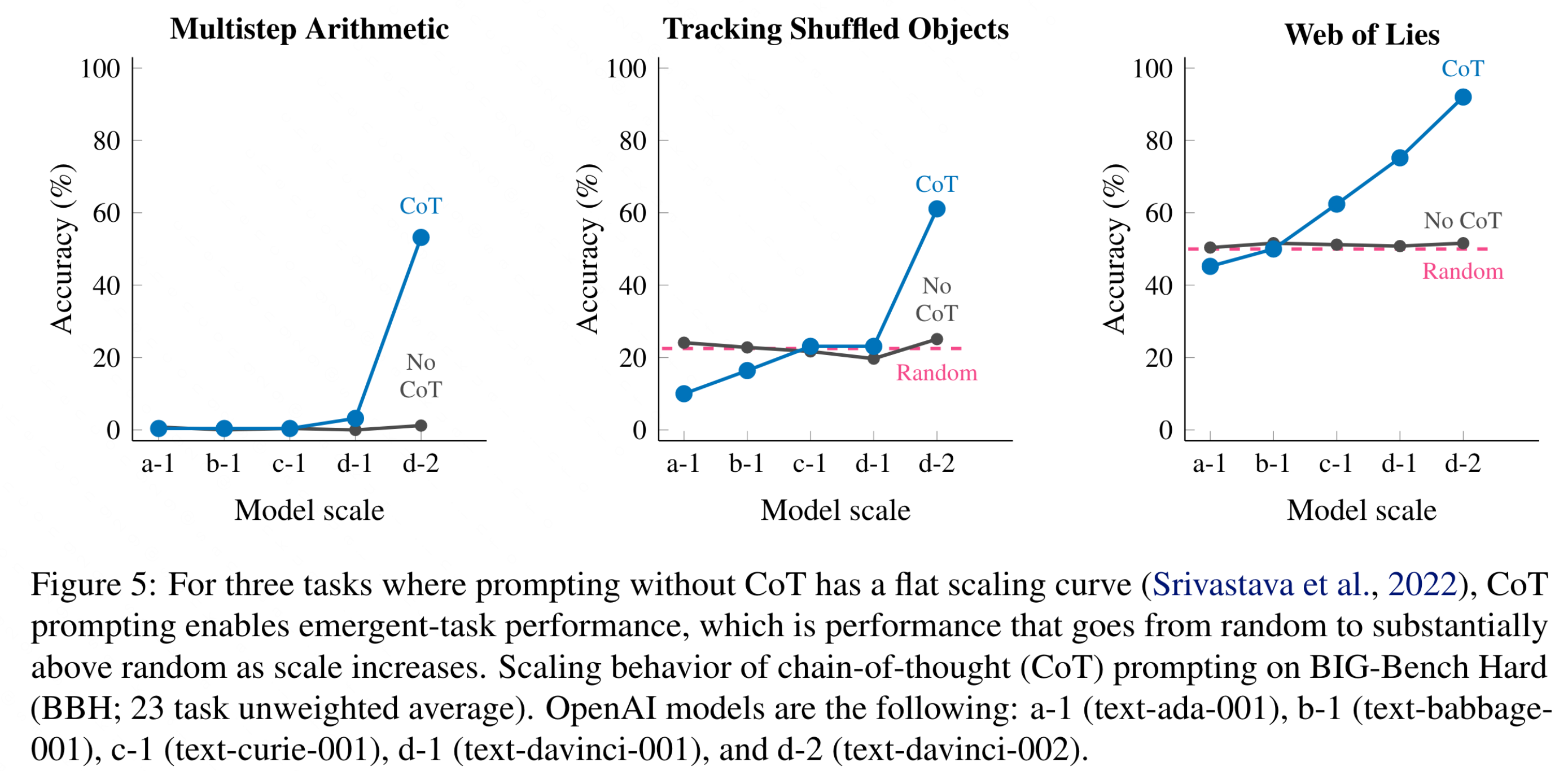
Finding that CoT enables emergent task performance on several BBH tasks with otherwise flat scaling curves.
四类task结果讨论
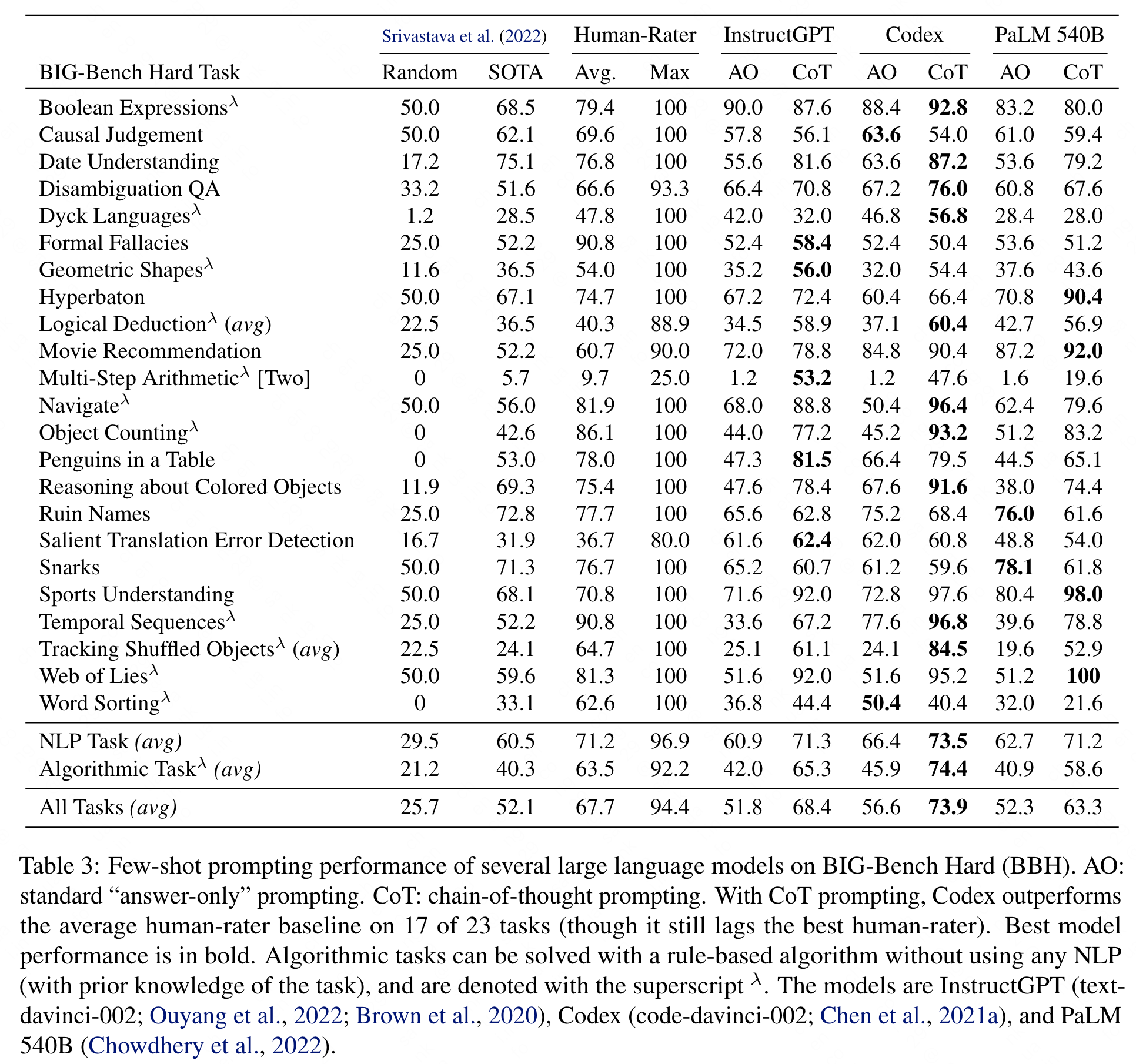
- Algorithmic and Multi-Step Arithmetic Reasoning: CoT appears to facilitate the decomposition of complex, multi-step problems into smaller, solvable problems in sufficiently large models. Codex shows better performance in following task instructions and exploiting algorithmic patterns based on the prompt exemplars compared to InstructGPT and PaLM. observe significant performance improvements with CoT prompting on Tracking Shuffled Objects (60.4% ↑), Multi-Step Arithmetic (46.4% ↑), Navigate (46.0% ↑), and Temporal Sequences (19.8% ↑) using the Codex model.
- Natural Language Understanding: PaLM and InstructGPT models typically perform better than Codex models. include Disambiguation QA, Hyperbaton (Adjective Ordering), Salient Translation Error Detection, and Snarks (Sarcasm Detection).
- Use of World Knowledge : require factual and general knowledge about the world as well as the common practices and presuppositions in the Western society. None of the language models perform better than the average reported human-rater performance.
- Multilingual Knowledge and Reasoning: one multilingual task, Salient Translation Error Detection, based on translation quality estimation and cross-lingual natural-language inference. Interestingly, we observe the improvement through CoT prompting only in PaLM
Failure analysis of CoT Prompting: lags behind answer-only prompting on three tasks—Causal Judgment, Ruin Names, and Snarks - across all three model families. Two of these tasks require use of world knowledge, for example common presuppositions, human perception and usage of humor
limitations
13 tasks are extremely difficult for authors of this paper; they require domain-specific knowledge or are not practically solvable within twenty minutes. We do not think these tasks can be attempted with CoT prompting, and we leave them as future work for more powerful models or prompting methods

From J. Wei et al., ‘Chain of Thought Prompting Elicits Reasoning in Large Language Models’. arXiv, Oct. 10, 2022. Accessed: Dec. 22, 2022. [Online]. Available: http://arxiv.org/abs/2201.11903
- Although chain of thought emulates the thought processes of human reasoners, this does not answer whether the neural network is actually “reasoning,”
- Second, although the cost of manually augmenting exemplars with chains of thought is minimal in the few-shot setting, such annotation costs could be prohibitive for finetuning (though this could potentially be surmounted with synthetic data generation, or zero-shot generalization)
- Third, there is no guarantee of correct reasoning paths, which can lead to both correct and incorrect answers; improving factual generations of language models is an open direction for future work
- Finally, the emergence of chain-of-thought reasoning only at large model scales makes it costly to serve in real-world applications; further research could explore how to induce reasoning in smaller models
Application
From J. Wei et al., ‘Chain of Thought Prompting Elicits Reasoning in Large Language Models’. arXiv, Oct. 10, 2022. Accessed: Dec. 22, 2022. [Online]. Available: http://arxiv.org/abs/2201.11903
- How much more can we expect reasoning ability to improve with a further increase in model scale?
- What other prompting methods might expand the range of tasks that language models can solve
Additional Reading
Zero-shot COT: “let’s think step-by-step”
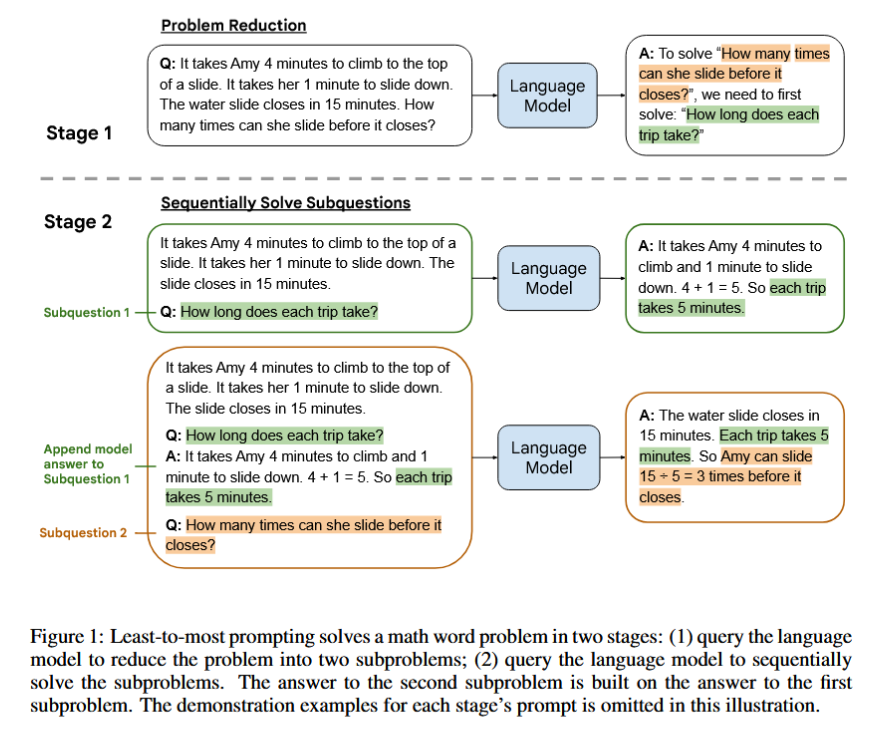
Least-to-Most:D. Zhou et al., ‘Least-to-Most Prompting Enables Complex Reasoning in Large Language Models’. arXiv, Oct. 06, 2022. Accessed: Feb. 01, 2023. [Online]. Available: http://arxiv.org/abs/2205.10625
Program of Thoughts Prompting(PoT): W. Chen, X. Ma, X. Wang, and W. W. Cohen, ‘Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks’. arXiv, Nov. 28, 2022. Accessed: Feb. 02, 2023. [Online]. Available: http://arxiv.org/abs/2211.12588

BIG-Bench (Srivastava et al., 2022) is a diverse evaluation suite that focuses on tasks believed to be beyond the capabilities of current language models.
Instruction Fine-Tuning: Fine-tuned LAnguage Net (FLAN), J. Wei et al., ‘Finetuned Language Models Are Zero-Shot Learners’, arXiv:2109.01652 [cs], Dec. 2021, Accessed: Dec. 03, 2021. [Online]. Available: http://arxiv.org/abs/2109.01652
LaMDA
PaLM