2020, ACL Task: MultiMedia Event Extraction
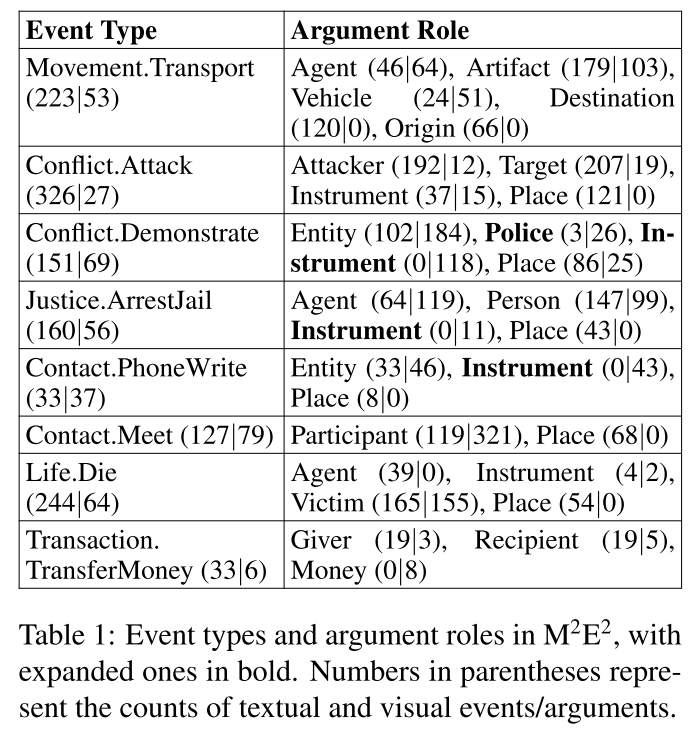
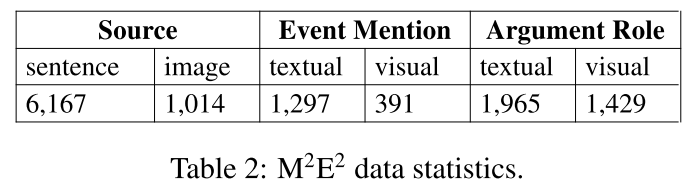
Introduce a new task, MultiMedia Event Extraction (M2E2), which aims to extract events and their arguments from multimedia documents. Construct the first benchmark and evaluation dataset for this task, which consists of 245 fully annotated news articles
Propose a novel method, Weakly Aligned Structured Embedding (WASE), that encodes structured representations of semantic information from textual and visual data into a common embedding space. which takes advantage of annotated unimodal corpora to separately learn visual and textual event extraction, and uses an image-caption dataset to align the modalities
数据
Each input document consists of:
- a set of images
M = {m1,m2, . . . } - and a set of sentences
S = {s1, s2, . . . } - a set of entities
T = {t1, t2, . . . }extracted from the document text

The tasks of M2E2
- Event Extraction: Given a multimedia document, extract a set of event mentions, where each event mention e has a type ye and is grounded on a text trigger word w or an image m or both $e = (y_e, {w,m})$.
- Argument Extraction: The second task is to extract a set of arguments of event mention e. Each argument a has an argument role type ya, and is grounded on a text entity t or an image object o (represented as a bounding box), $a = (y_a, {t, o})$
Two types of bounding boxes:
- union bounding box: for each role, we annotate the smallest bounding box covering all constituents
- instance bounding box: for each role, we annotate a set of bounding boxes, where each box is the smallest region that covers an individual participant

方法
represent each image or sentence as a graph, where each node represents an event or entity and each edge represents an argument role.
the training phase contains three tasks:
Text event extraction
Text Structured Representation: run the CAMR parser (Wang et al., 2015b,a, 2016) to generate an AMR graph. based on the named entity recognition and part- of-speech (POS) tagging results from Stanford CoreNLP (Manning et al., 2014)
Embedding: pre-trained GloVe word embedding (Pennington et al., 2014), POS embedding, entity type embed- ding and position embedding
Encode embedding: Bi-LSTM
Encode AMR: AMR graph as input to GCN:

For each entity t, we obtain its representation $t^C$ by averaging the embeddings of its tokens
Event and Argument Classifier
- use BIO tag schema to decide trigger word boundary, classify each word w into event types $y_e$
- classify entity t into argument role $y_a$
训练时, 用Ground-true entity
测试时, 用named entity extractor
Image Event Extraction (Section 3.3)
Image Structured Representation: represent each image with a situation graph, the central node is labeled as a verb v (e.g., destroying), and the neighbor nodes are arguments labeled as {(n, r)}, where n is a noun (e.g., ship) derived from WordNet synsets (Miller, 1995) to indicate the entity type, and r indicates the role (e.g., item) played by the entity in the event, based on FrameNet (Fillmore et al., 2003).
two methods to construct situation graphs:
Object-based Graph: object detection, and obtain the object bounding boxes detected by a Faster R-CNN (Ren et al., 2015) model trained on Open Images (Kuznetsova et al., 2018) with 600 object types (classes). employ a VGG-16 CNN (Si- monyan and Zisserman, 2014) to extract visual features of an image m and and another VGG-16 to encode the bounding boxes {oi}. apply a Multi-Layer Perceptron (MLP) to predict a verb embedding from m and another MLP to predict a noun embedding for each oi
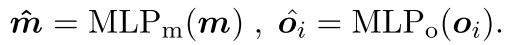
compare the predicted verb embedding to all verbs v in the imSitu taxonomy in order to classify the verb, and similarly compare each predicted noun embedding to all imSitu nouns n which re- sults in probability distributions. where v and n are word embeddings initialized with GloVE.
use another MLP with one hidden layer followed by Softmax (σ) to classify role ri for each object oi
define the situation loss
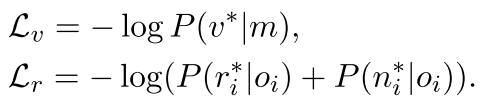
Attention-based Graph
Many salient objects such as bomb, stone and stretcher are not covered in these ontologies. Hence, propose an open-vocabulary alternative to the object-based graph construction model.
and cross- media alignment (Section 3.4)
效果
Compared to unimodal state-of-the-art methods, our approach achieves 4.0% and 9.8% absolute F-score gains on text event argument role labeling and visual event extraction.