2017, EMNLP
data: FB15K-237, FB15K
task: Knowledge Graph Reasoning
Use a policy-based agent with continuous states based on knowledge graph embeddings, which reasons in a KG vector space by sampling the most promising relation to extend its path.
方法
RL 系统包含两部分,
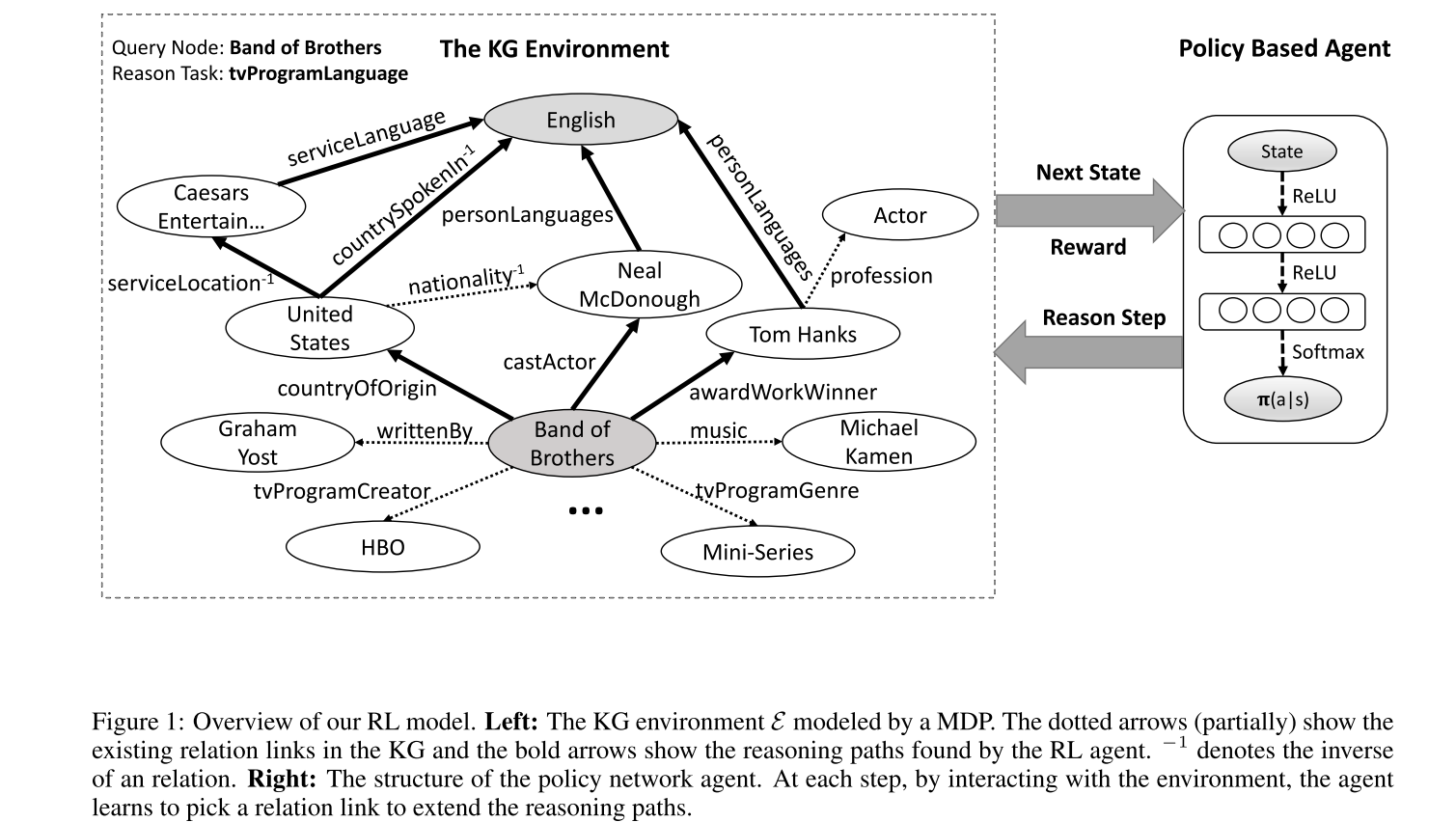
- 第一部分是外部环境,指定了 智能体 和知识图谱之间的动态交互。环境被建模为马尔可夫决策过程。
- 系统的第二部分,RL 智能体,表示为策略网络,将状态向量映射到随机策略中。神经网络参数通过随机梯度下降更新。相比于 DQN,基于策略的 RL 方法更适合该知识图谱场景。一个原因是知识图谱的路径查找过程,行为空间因为关系图的复杂性可能非常大。这可能导致 DQN 的收敛性变差。另外,策略网络能学习梯度策略,防止 智能体 陷入某种中间状态,而避免基于值的方法如 DQN 在学习策略梯度中遇到的问题。
关系推理的强化学习
行为 给定一些实体对和一个关系,我们想让 智能体 找到最有信息量的路径来连接这些实体对。从源实体开始,智能体 使用策略网络找到最有希望的关系并每步扩展它的路径直到到达目标实体。为了保持策略网络的输出维度一致,动作空间被定义为知识图谱中的所有关系。
状态 知识图谱中的实体和关系是自然的离散原子符号。现有的实际应用的知识图谱例如 Freebase 和 NELL 通常有大量三元组,不可能直接将所有原子符号建模为状态。为了捕捉这些符号的语义信息,我们使用基于平移的嵌入方法,例如 TransE 和 TransH 来表示实体和关系。这些嵌入将所有符号映射到低维向量空间。在该框架中,每个状态捕捉 智能体 在知识图谱中的位置。在执行一个行为后,智能体 会从一个实体移动到另一个实体。两个状态通过刚执行的行为(关系)由 智能体 连接。第 t 步的状态向量:
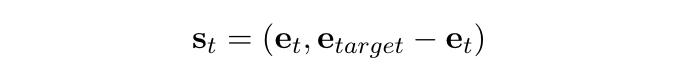
其中 e.t 表示当前实体结点的嵌入,e.target 表示目标实体的嵌入。在最初状态,e.t 即 e.source。我们没有在状态中加入推理关系,因为在寻路过程中推理关系的嵌入保持不变,不利于训练。然而,我们发现通过使用一组特定关系的正样本训练 RL 代理,该 智能体 可以成功地发现关系语义。
奖励 对于我们的环境设置,智能体 可以执行的操作数量可能非常大。换句话说,错误的顺序决策比正确的顺序决策多得多。这些错误的决策序列的数量会随着路径的长度呈指数增长。
- Global accuracy:

- Path efficiency
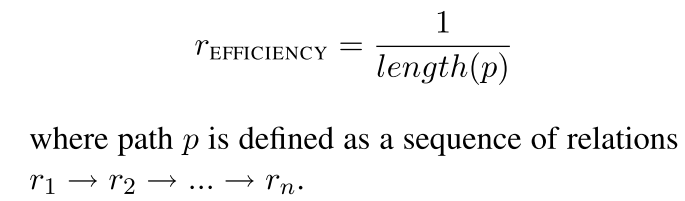
- Path diversity:

策略网络 我们使用全连接神经网络来参数化策略函数,它讲状态向量映射到所有可能行为的概率分布上。神经网络包含两个隐藏层,每一层后接 ReLU。输出层通过 softmax 函数归一化。
3.2 训练
对于一个典型的KG, RL 智能体 常常面临上千种可能的操作。换句话说,策略网络的输出层具有较大的维数。由于关系图的复杂性和较大的动作空间,如果直接采用 RL 算法中典型的试错推理来训练RL模型,将会导致 RL 模型收敛性很差。经过长时间的训练,智能体都可能无法找到任何有价值的路径。
为了解决这个问题,我们从一个监督策略开始我们的训练,这个策略的灵感来自 AlphaGo 使用的模仿学习流水线。在围棋游戏中,玩家每走一步都要面对近 250 种可能的合法走法。直接训练智能体从原始动作空间中挑选动作可能是一项困难的任务。AlphaGo 首先使用专家训练一个有监督的策略网络。在该例子中,使用随机的广度优先搜索(BFS)训练监督策略。
监督策略学习
对于每个关系,我们首先使用所有正样本(实体对)的子集来学习有监督的策略。对于每个正样本(esource, etarget),一个两端 BFS 被用于找到实体之间的正确路径。对于路径 p,使用蒙塔卡洛策略梯度(REINFORCE 方法)来最大化期望的累积奖励。

原生 BFS 是有偏的搜索算法,它倾向于使用短路径。当插入这些有偏向的路径时,agent 很难找到可能有用的较长路径。我们希望路径仅由定义的奖励函数控制。为了防止偏向搜索,我们采用了一种简单的技巧为 BFS 添加一些随机机制。我们不是直接搜索 esource 和 etarget 之间的路径,而是随机选择一个中间节点einter,然后在(esource,einter)和(einter,etarget)之间进行两个 BFS。连接的路径用于训练智能体。监督学习可以节省智能体从失败行为中学习的大量精力。借助所学的经验,我们然后训练智能体寻找理想的路径。
Retraining with Rewards
为了找到受奖励函数控制的推理路径,我们使用奖励函数来限制监督策略网络。对于每个关系,一个实体对的推理被视为一个事件(episode)。从源结点开始,智能体根据随机策略选择关系,它是所有关系上的概率分布,以扩展推理路径。关系链接可能引向一个新实体,或者失败。这些失败的步骤可能导致智能体获得负奖励。智能体在失败步骤后保持状态。由于智能体遵循随机策略,所以智能体不会因为重复错误的步骤而陷入困境。为了提高训练效率,我们将训练集长度设定一个上限。上限达到时,如智能体仍未找到目标实体则事件结束。每个事件结束后,策略网络通过以下梯度进行更新:

3.3 Bi-directional Path-constrained Search
In a typical KG, one entity node can be linked to a large number of neighbors with the same relation link. If we verify the formula from the inverse direction. The number of intermediate nodes can be tremendously decreased.
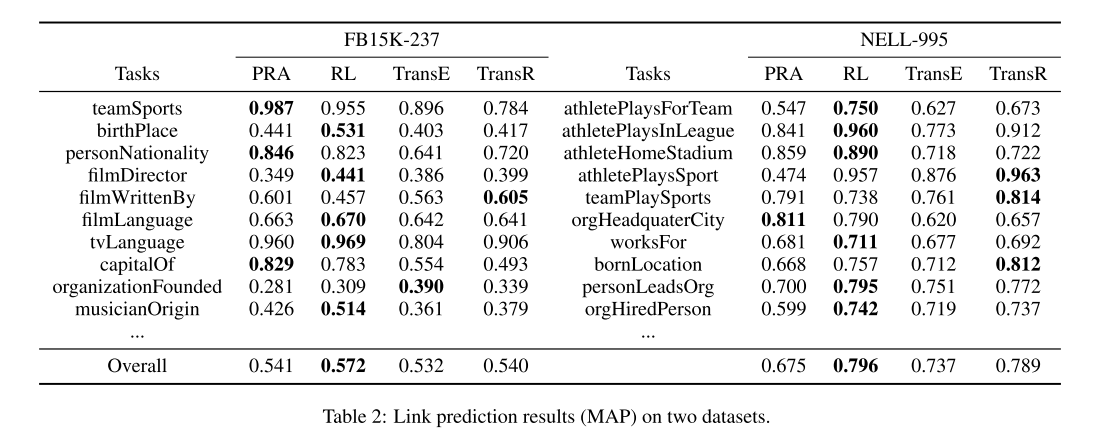
4 Experiments
we explore two standard KG reason- ing tasks: link prediction (predicting target en- tities) and fact prediction (predicting whether an unknown fact holds or not).
4.1 Dataset and Settings
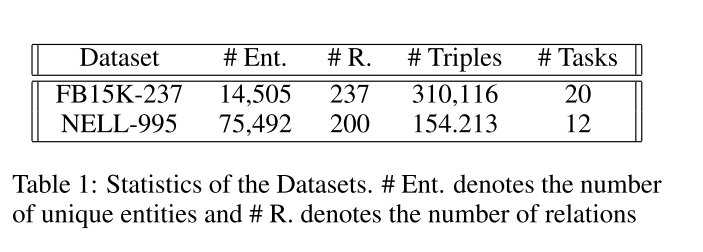
The triples in FB15K-237 (Toutanova et al., 2015) are sampled from FB15K (Bordes et al., 2013) with redun- dant relations removed.
4.3 Results