DeepSeek-AI, et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948, arXiv, 22 Jan. 2025. arXiv.org, https://doi.org/10.48550/arXiv.2501.12948.
Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Large language models (LLMs) have made remarkable strides in mimicking human-like cognition, but their ability to reason through complex problems—from math proofs to coding challenges—remains a frontier. In a recent breakthrough, DeepSeek-AI introduces DeepSeek-R1, a family of reasoning-focused models that leverages reinforcement learning (RL) to unlock advanced reasoning capabilities, without relying on traditional supervised fine-tuning (SFT) as a crutch. The paper “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning” unveils a paradigm shift in how we train LLMs to think critically, with implications for both research and real-world applications.
The Power of Pure RL: DeepSeek-R1-Zero’s Emergent Reasoning
At the heart of the research is DeepSeek-R1-Zero, a model trained entirely via large-scale RL on a base model (DeepSeek-V3-Base) without any SFT data. This “pure RL” approach is revolutionary: by using Group Relative Policy Optimization (GRPO) and a rule-based reward system (focused on accuracy and format), the model spontaneously develops sophisticated reasoning behaviors.
One of the most striking findings is how DeepSeek-R1-Zero evolves autonomous problem-solving strategies. For instance, on the AIME 2024 math benchmark, its pass@1 accuracy skyrocketed from 15.6% to 71.0% through RL training. Even more impressively, using majority voting, this accuracy surged to 86.7%, matching the performance of OpenAI’s o1-0912. The model also exhibits “aha moments”—intermediate checkpoints where it suddenly learns to revisit and refine its initial reasoning, like a human thinker having an epiphany.
But pure RL isn’t perfect. DeepSeek-R1-Zero struggled with readability and language mixing, prompting the development of DeepSeek-R1—a refined version that incorporates a “cold start” of curated Chain-of-Thought (CoT) data and a multi-stage training pipeline.
DeepSeek-R1: Balancing Reasoning and Readability
DeepSeek-R1 addresses R1-Zero’s limitations by integrating two key improvements:
- Cold-start fine-tuning: Thousands of human-curated CoT examples kickstart the model, ensuring cleaner output formats and reducing language mixing.
- Multi-stage RL-SFT cycles: After RL training for reasoning, the model undergoes supervised fine-tuning on a mix of reasoning and non-reasoning data (e.g., writing, factual QA), then another RL phase to align with human preferences.
The result? DeepSeek-R1 achieves performance on par with OpenAI’s o1-1217 across critical benchmarks. On AIME 2024, it hits 79.8% pass@1, slightly outperforming o1-1217 (79.2%). On MATH-500, it scores 97.3%, matching o1-1217’s excellence. In coding, it reaches a Codeforces rating of 2,029, outperforming 96.3% of human participants.
Here is the overall training pipeline show in the excellent images created by SirrahChan. (2025, June 17). visualizing the training pipeline for DeepSeek-R1(-Zero) and the distillation to smaller models. Twitter. https://x.com/SirrahChan/status/1881540279783887036
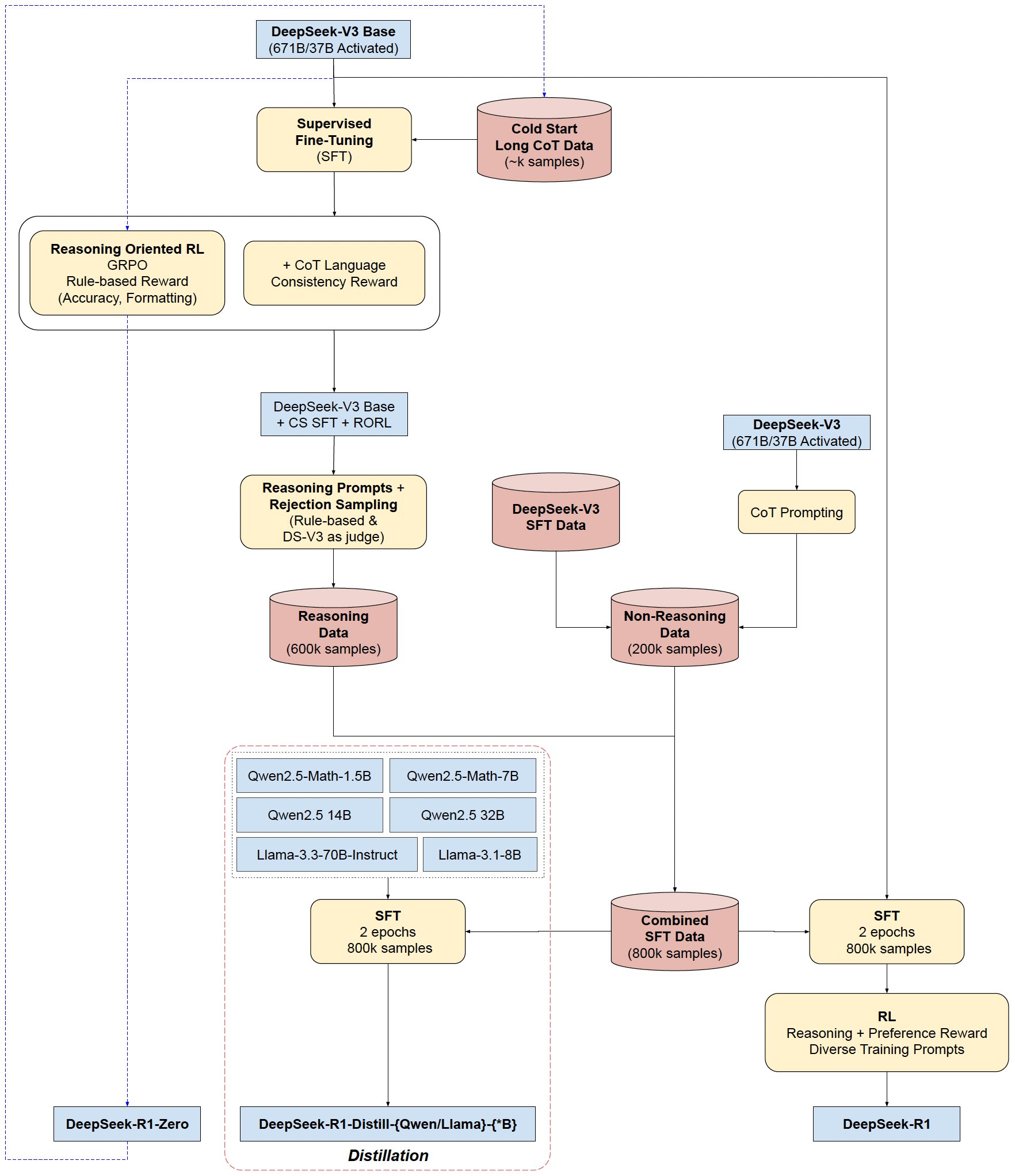
Distillation: Empowering Small Models to Reason
A major highlight of the research is the effectiveness of distilling reasoning capabilities from DeepSeek-R1 into smaller models. By fine-tuning open-source bases like Qwen and Llama on 800K samples generated by DeepSeek-R1, the team created lightweight models that punch far above their weight.
- DeepSeek-R1-Distill-Qwen-7B achieves 55.5% on AIME 2024, surpassing the 32B QwQ-32B-Preview.
- DeepSeek-R1-Distill-Qwen-32B scores 72.6% on AIME, 94.3% on MATH-500, and 57.2% on LiveCodeBench—outperforming most open-source models and rivaling o1-mini.
This distillation approach proves that larger models’ reasoning patterns can be transferred to smaller architectures, offering a cost-effective path to deploy powerful reasoning in real-world applications.
Why This Matters: Rethinking LLM Training Paradigms
DeepSeek-R1 challenges the conventional wisdom that SFT is indispensable for building reasoning ability. By demonstrating that pure RL can drive emergent reasoning—and that distillation can spread these capabilities to smaller models—DeepSeek-AI opens new doors for the field:
- Reduced dependency on labeled data: RL-based training requires less human annotation, making it more scalable.
- Democratizing advanced reasoning: Distilled models enable researchers and developers to access cutting-edge reasoning without massive compute resources.
- Ethical alignment through RL: The multi-stage pipeline allows for explicit alignment with human preferences (e.g., readability, safety), reducing risks of harmful outputs.
What’s Next: Open Source and Beyond
DeepSeek-AI has open-sourced DeepSeek-R1, R1-Zero, and all six distilled models (1.5B to 70B), inviting the community to build upon their work. Future plans include improving multi-language capabilities, addressing prompt sensitivity, and enhancing software engineering tasks—where RL training data is currently limited.
In a world where LLM reasoning is increasingly critical for science, education, and industry, DeepSeek-R1 marks a pivotal step toward more autonomous, efficient, and accessible AI reasoning. As the paper concludes, “advancing beyond the boundaries of intelligence may still require more powerful base models and large-scale reinforcement learning”—but the journey has just begun.
To explore the models and code, visit the DeepSeek-AI repository and dive into the full research hehttps://arxiv.org/abs/2501.12948re.