Bavarian, Mohammad, et al. Efficient Training of Language Models to Fill in the Middle. arXiv:2207.14255, arXiv, 28 July 2022. arXiv.org, http://arxiv.org/abs/2207.14255. data: https://www.github.com/openai/human-eval-infilling
TL:DR
Autoregressive language models can effectively learn to infill text by moving a span of text from the middle of a document to its end, without harming the original generative capability. The training models with this technique, called fill-in-the-middle (FIM), is useful, simple, and efficient, and should be used by default in future autoregressive language models. The study provides best practices and strong default settings for training FIM models and releases infilling benchmarks to aid future research.
- FIM-for-free property, just transform a portion of the training dataset by randomly splitting documents into three parts and moving the middle section to the end,
document → (prefix, middle, suffix) → (prefix, suffix, middle), which can be concatenated by sentinel tokens. - Best practices for FIM in pretraining: They conducted comprehensive ablations to clarify the effects of various hyperparameters related to training FIM models. Specifically, the FIM rate (probability of applying FIM transformation), different FIM transformation variants, and middle span selection.
- Finetuning inefficiency: they demonstrate that finetuning with FIM is computationally inefficient. Learning FIM during finetuning requires a significant amount of additional compute to achieve comparable performance levels.
- New infilling benchmarks: random span infilling and random span infilling light.
- Need for sampling evaluations: modifying different hyperparameters during FIM training can result in minimal changes in FIM test losses, but significant differences in sampling-based benchmarks. These benchmarks are not only more representative of real-world use cases, but they also reveal improvements that may be overlooked by relying solely on test losses. This finding is crucial, as scaling laws analysis often relies solely on test losses, which can be misleading without additional evaluations.
Why Infilling is Important?
Iinfilling is important for applications that require context before and after the point of generation, such as coding assistants, docstring generation, import statement generation, or completing a partially written function.
Why FIM
Transformer based language models can be divided into three broad classes: encoder-only models like BERT, encoder-decoder models like T5, and causal decoder-based models like GPT.
- Encoder-only models are trained with a masked language modeling objective,
- Encoder-decoder models are trained with a span prediction objective.
- Causal decoder-based models are trained using the left-to-right next token prediction objective.
All model classes are limited in infilling, which involves generating text within a prompt while conditioning on both a prefix and a suffix.
- Left-to-right models can only condition on the prefix.
- Encoder-only and encoder-decoder models can condition on suffixes, but the lengths of infill regions seen during training are typically too short for practical use.
Method
FIM
Apply a random transformation to the dataset. They explore two distinct implementations: document-level and context-level. The key difference between the two lies in the stage of the data loading pipeline where the FIM transformation takes place. This decision is driven by the fact that a lengthy document can be divided into multiple contexts, while a context can encompass multiple documents if the documents are relatively short.
Document-level FIM:
- With a probability parameter p (referred to as the FIM rate, p = 0.5 is used for the primary set of models), each document is divided into a prefix, a middle, and a suffix. the term FIM model is used to refer to any model that is trained on a mixture of FIM transformed and normal left-to-right data. Models that are trained without any FIM data, i.e., with a 0% FIM rate, are referred to as AR models.
- This split occurs before tokenization, when the document is still represented as a character sequence.
- The document is randomly split uniformly, such that the expected length of each part (prefix, middle, and suffix) is 1/3 of the full document length.
- Each of the three sections is encoded separately, and sentinel tokens (
,
, and ) are prepended to the beginning of each section. - The three sections are concatenated in the order prefix, suffix, and middle, along with their sentinel tokens, to form the tokenized version of the FIM document:
<PRE> ◦ Enc(prefix) ◦ <SUF> ◦ Enc(suffix) ◦ <MID> ◦ Enc(middle) \tag{(PSM)}, where ◦ denotes concatenation. - Different documents, whether FIM or AR, are concatenated with
and given to the model during training. - The loss is kept on all three sections (prefix, middle, and suffix), so FIM training does not cause a decrease in the autoregressive learning signal. Preliminary experiments suggest that keeping the loss on all three sections is crucial for the FIM-for-free property to hold.
- It is important to always train on the
tokens as it signals a successful join to the suffix. - During inference, the prefix and suffix are encoded and used to prompt the model with
<PRE> ◦ Enc(prefix) ◦ <SUF> ◦ Enc(suffix) ◦ <MID>. \tag{(PSM inference)}. The model generates samples until it produces thetoken, indicating successful connection of the prefix and suffix. If the token is not generated within a reasonable inference token budget, it suggests difficulty in connecting the prefix and suffix, and EOT aware best-of-n sampling is used to improve sample quality.
SPM mode
- To improve key-value caching during inference, SPM mode is introduced, where the suffix, prefix, and middle order is swapped, use the ordering
[suffix, prefix, middle]. This is because SPM avoids invalidation of keys and values computed in the suffix section when tokens are appended to the prefix. Note that superiority of SPM caching is not universal and may depend on the applications. - Two variants of SPM encoding are presented. SPM variant 1 uses
<SUF> ◦ Enc(suffix) ◦ <PRE> ◦ Enc(prefix) ◦ <MID> ◦ Enc(middle) ◦ <EOT>. (SPM variant 1), while SPM variant 2 uses<PRE> ◦ <SUF> ◦ Enc(suffix) ◦ <MID> ◦ Enc(prefix) ◦ Enc(middle) ◦ <EOT>. (SPM variant 2). The reason for using SPM variant 2 is to avoid creating a separation between PSM and SPM, which may result in less transfer between them. My understanding is that this is compatible with empty prefix in PSM mode. Since SPM is already a swap mode, it does not have to strictly follow thesentinel A ◦ Enc(A)format. - However, SPM variant 1 has its own advantages, such as being stronger in handling subtokens at the end of the prefix. The choice of which variant to use may depend on the application. In this work, SPM variant 2 is used to emphasize joint training of PSM and SPM and to maximize transfer between them.
- However, minor changes to the suffix may invalidate the cache for the prefix in SPM mode.
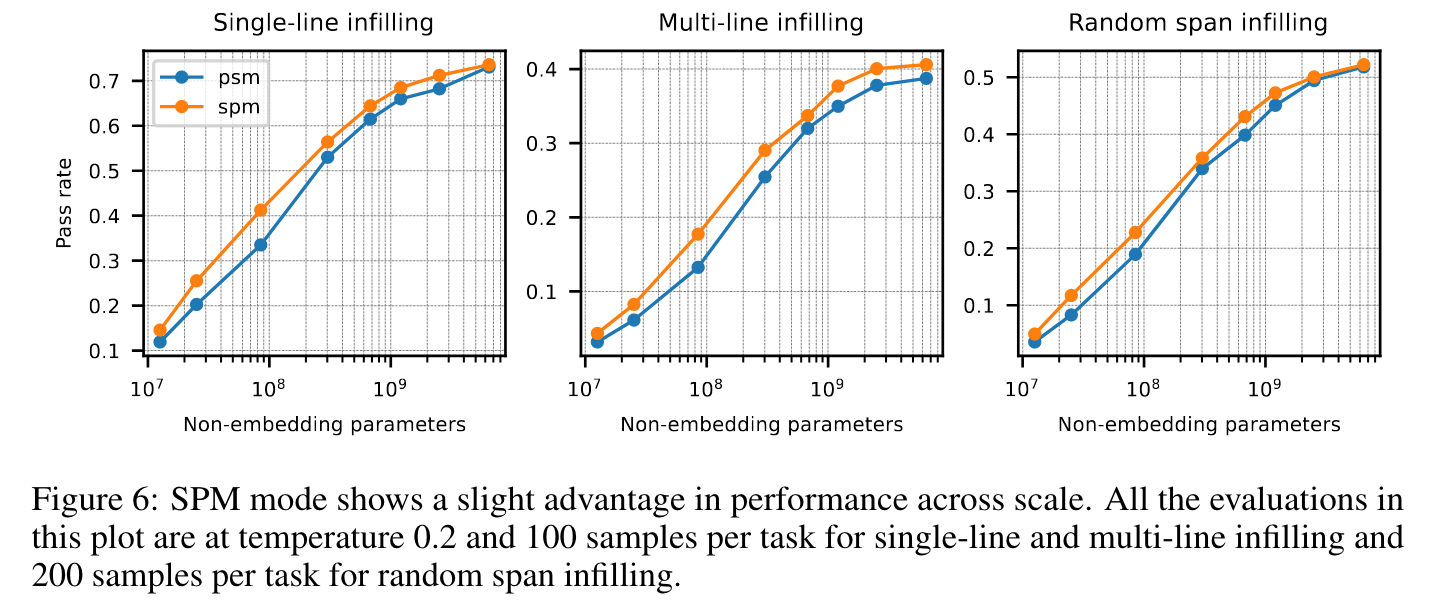
- SPM also has a slight edge over PSM in infilling benchmarks.
- The FIM transformation is applied with 50% probability in both PSM and SPM modes to handle both types of formatting in inference. The placement of sentinel tokens in SPM is important when training jointly on SPM and PSM.
Context-level FIM
In language model training, documents are often joined with a boundary token, referred to as
- Training data contains lots of documents. When applying FIM to long documents, a joined by
then chunked operation can result in fragmented FIM data where the entire prefix or suffix could get cut out of the context during chunking. - To address this issue, FIM can be applied after the chunking step. A context slice may have multiple documents in them joined with the
boundary token. The context slice is split based on . At this point, these documents are already tokenized, so applying FIM at the token level is straightforward. Some of the resulting documents are randomly selected to be turned into FIM examples based on a given FIM rate. The examples are then joined again with , and the resulting slice is trimmed to the model’s context length. - This technique can boost performance relative to document-level FIM, and adopt context-level FIM in all the main FIM runs in this work.
Evaluation
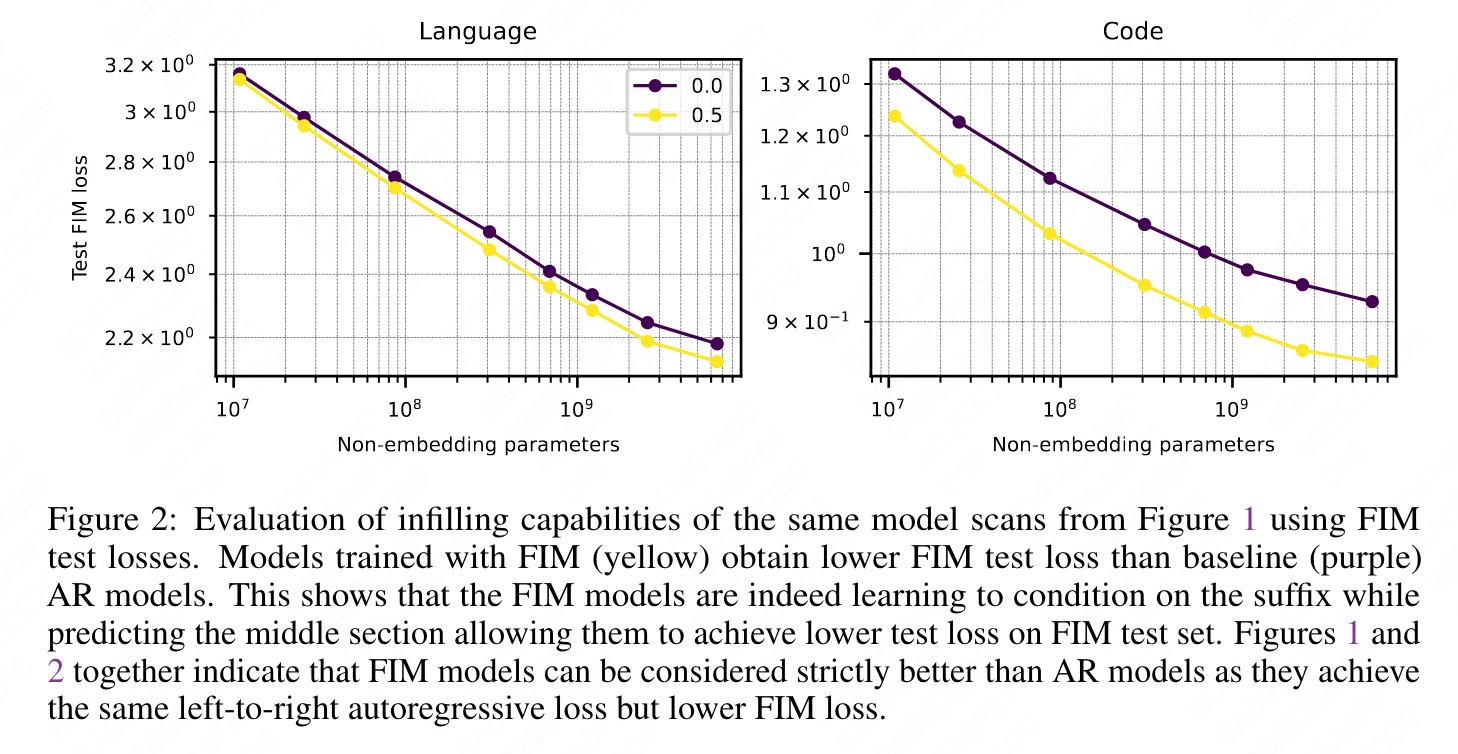
- The left-to-right test loss is unaffected even though FIM models see the data in its original form half the time, and are simultaneously learning a new skill.
-
They trained a series of models with varying numbers of parameters, ranging from 50M to 6.9B, from scratch with and without 50% FIM augmentation on both natural language and code domains. They found that the left-to-right test loss was not affected by the FIM augmentation, even though the FIM models saw the data in its original form only half the time and were simultaneously learning a new skill.
-
Test los

-
-
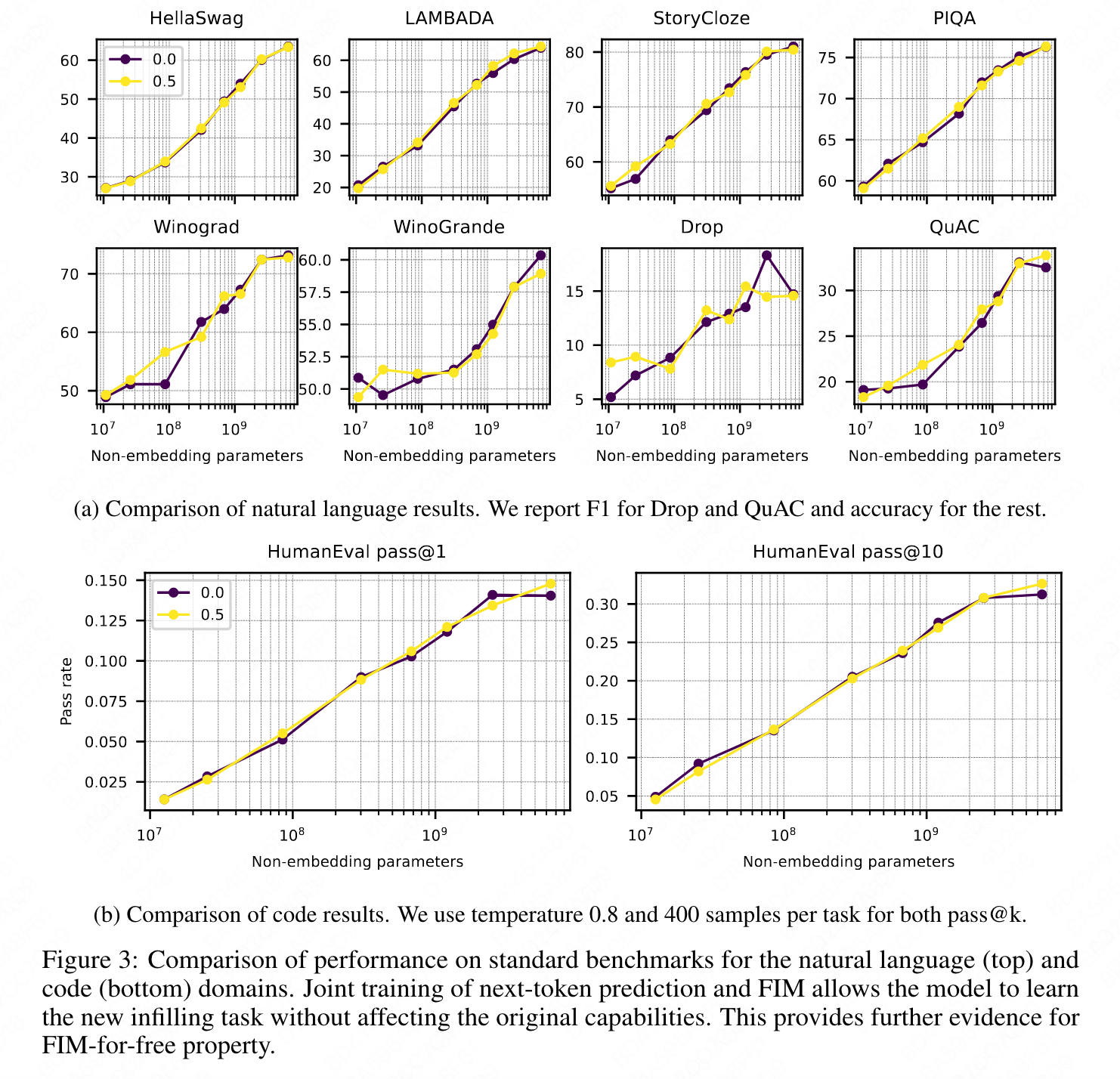
Joint FIM pretraining does not result in any degradation in standard AR benchmarks as the performance matches within error for both natural language and code.
-
However, the authors noted that test loss alone is not always sufficient to evaluate model performance. To strengthen their results, they evaluated their models on a suite of standard downstream benchmarks. The performance of the FIM models matched that of the non-FIM models within the margin of error for both natural language and code. The results are presented in Figure 3.
-
NLP benchmarks
-
-
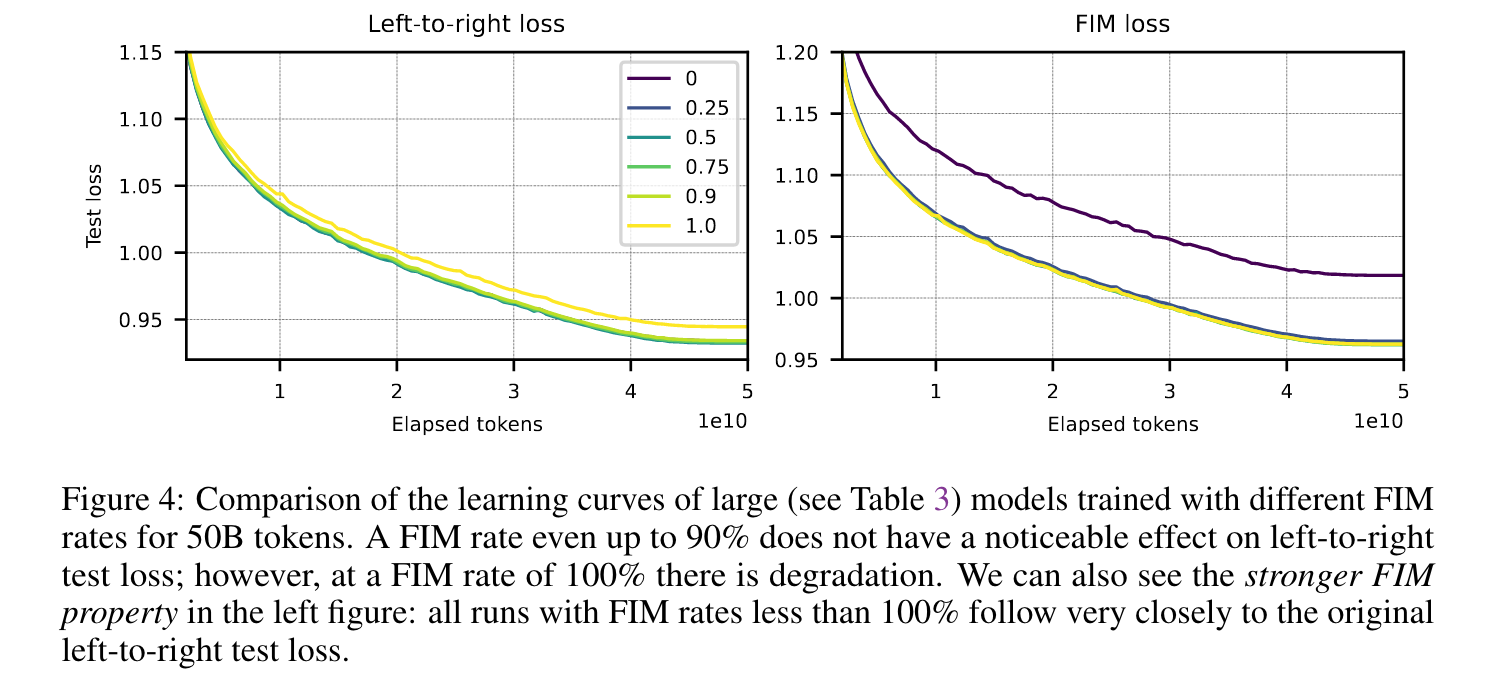
The left plot in Figure 4 provides evidence that a FIM rate even up to 90% does not cause any degradation in left-to-right capabilities.
- However, there is a clear sign of degradation in ordinary AR test loss with 100% FIM rate.
- This suggests that evaluating the FIM capabilities of the models cannot be done solely by considering language modeling perplexity measures such as test loss, but non-loss based evaluations should also be taken into account.
-
SPM is slightly stronger than PSM in the benchmarks in general as evidenced by Figure 6