Bit Map
Bit-map用一个bit位来标记某个元素对应的Value, 而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。
假设我们要对0-7内的5个元素4,7,2,5,3排序(假设这些元素没有重复)。那么我们就可以采用Bit-map的方法来达到排序的目的。要表示8个数,我们就只需要8个Bit(1Bytes),
- 首先我们开辟1Byte的空间,将这些空间的所有Bit位都置为0,
0 0 0 0 0 0 0 0. - 然后遍历这5个元素,首先第一个元素是4,那么就把4对应的位置设为1,
p+(i/8)|(0x01<<(i%8)), 这里默认为Big-ending,0 0 0 0 1 0 0 0. - 然后再处理第二个元素7,将第八位置为1,,接着再处理第三个元素,一直到最后处理完所有的元素,将相应的位置为1,这时候的内存的Bit位的状态
0 0 1 1 1 1 0 1 - 遍历一遍Bit区域,把
1的索引依次输出(2,3,4,5,7),这样就达到了排序的目的。
算法的关键是如何确定十进制的数映射到二进制bit位的map图。算法占用很少内存,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M。缺点是不能有重复数据。
Map映射表
假设需要排序或者查找的总数N=10000000,那么我们需要申请内存空间的大小为int a[1 + N/32],其中:a[0]在内存中占32位, 可以对应十进制数0-31,依次类推:
bitmap表为:
a[0]--------->0-31
a[1]--------->32-63
a[2]--------->64-95
a[3]--------->96-127
..........
十进制数需要转换为对应的bit位
位移转换
将十进制数转换为对应的bit位, 申请一个int一维数组,作为32列的二维数组,
int a[0] |0000000000000000000000000000000000000|
int a[1] |0000000000000000000000000000000000000|
………………
int a[N] |0000000000000000000000000000000000000|
例如十进制0,对应在a[0]第一位: 00000000000000000000000000000001
- 求十进制
0-N对应在数组a的索引:十进制0-31,对应a[0],先由十进制数n转换为与32的余可转化为对应在数组a中的索引0。比如n=24,那么 n/32=0,则24对应a[0]。又比如n=60, 那么n/32=1,则60对应a[1]。 - 求
0-N对应0-31中的数:十进制0-31就对应0-31,而32-63则对应也是0-31,即给定一个数n可以通过模32求得对应0-31中的数。 - 利用移位0-31使得对应32bit位为1. 找到对应0-31的数为M, 左移M位:即
2 ^ M, 置1.
Bloom Filter
为了降低键值冲突的概率,Bloom Filter使用了多个哈希函数:创建一个m位BitSet,先将所有位初始化为0,然后选择k个不同的哈希函数。第i个哈希函数对字符串str哈希的结果记为h(i, str),且h(i, str)的范围是0到m-1 。
对于字符串str,分别计算h(1, str), h(2, str), ... h(k, str), 以这些哈希值作为索引, 将BitSet的对应位置的位设为1, 这样就把str映射到BitSet的k个二进制位了.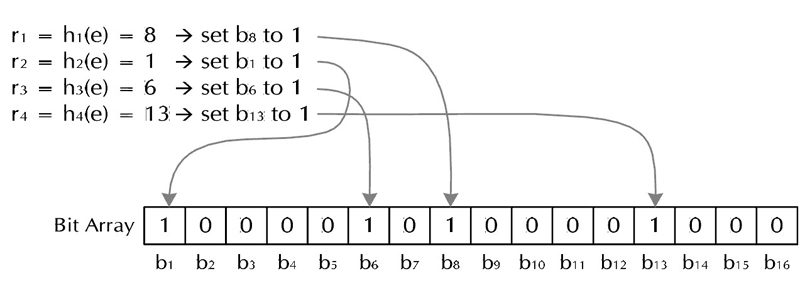
如果要检查某string是否已经被记录在BitSet中, 只需要计算其哈希值数组, 并检查BitSet上对应位置的值是否为1, 若对应位置中有任何一个不是1, 那么该字符串一定没有被记录过, 若全部对应位置都为1, 那么按照false positive认为该字符串已经被记录过了(但不是100%肯定).
删除操作会影响到其他字符串。如果需要删除字符串的功能,使用Counting bloomfilter(CBF),这是一种Bloom Filter的变体,CBF将Bloom Filter每一个Bit改为一个计数器,这样就可以实现删除字符串的功能了。
Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。
所以Bloom Filter适用以下几个特点:
- 只要返回数据不存在,则肯定不存在。
- 返回数据存在,但只能是大概率存在。
- 不能清除其中的数据。
BloomFilter的应用很多,比如数据库、爬虫(用爬虫抓取网页时对网页url去重)、防缓存击穿等。特别是需要精确知道某个数据不存在时做点什么事情就非常适合布隆过滤。 Goolge在BigTable中就使用了BloomFilter,以避免在硬盘中寻找不存在的条目。
实现
Java实现
作者:crossoverJie
链接:https://zhuanlan.zhihu.com/p/50926087
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
public class BloomFilters {
/**
* 数组长度
*/
private int arraySize;
/**
* 数组
*/
private int[] array;
public BloomFilters(int arraySize) {
this.arraySize = arraySize;
array = new int[arraySize];
}
/**
* 写入数据
* @param key
*/
public void add(String key) {
int first = hashcode_1(key);
int second = hashcode_2(key);
int third = hashcode_3(key);
array[first % arraySize] = 1;
array[second % arraySize] = 1;
array[third % arraySize] = 1;
}
/**
* 判断数据是否存在
* @param key
* @return
*/
public boolean check(String key) {
int first = hashcode_1(key);
int second = hashcode_2(key);
int third = hashcode_3(key);
int firstIndex = array[first % arraySize];
if (firstIndex == 0) {
return false;
}
int secondIndex = array[second % arraySize];
if (secondIndex == 0) {
return false;
}
int thirdIndex = array[third % arraySize];
if (thirdIndex == 0) {
return false;
}
return true;
}
/**
* hash 算法1
* @param key
* @return
*/
private int hashcode_1(String key) {
int hash = 0;
int i;
for (i = 0; i < key.length(); ++i) {
hash = 33 * hash + key.charAt(i);
}
return Math.abs(hash);
}
/**
* hash 算法2
* @param data
* @return
*/
private int hashcode_2(String data) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < data.length(); i++) {
hash = (hash ^ data.charAt(i)) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
return Math.abs(hash);
}
/**
* hash 算法3
* @param key
* @return
*/
private int hashcode_3(String key) {
int hash, i;
for (hash = 0, i = 0; i < key.length(); ++i) {
hash += key.charAt(i);
hash += (hash << 10);
hash ^= (hash >> 6);
}
hash += (hash << 3);
hash ^= (hash >> 11);
hash += (hash << 15);
return Math.abs(hash);
}
}
Guava 实现
@Test
public void guavaTest() {
long star = System.currentTimeMillis();
BloomFilter<Integer> filter = BloomFilter.create(
Funnels.integerFunnel(),
10000000,
0.01);
for (int i = 0; i < 10000000; i++) {
filter.put(i);
}
Assert.assertTrue(filter.mightContain(1));
Assert.assertTrue(filter.mightContain(2));
Assert.assertTrue(filter.mightContain(3));
Assert.assertFalse(filter.mightContain(10000000));
long end = System.currentTimeMillis();
System.out.println("执行时间:" + (end - star));
}
构造方法有两个比较重要的参数,一个是预计存放多少数据,一个是可以接受的误报率。Guava 会通过你预计的数量以及误报率帮你计算出你应当会使用的数组大小 numBits 以及需要计算几次 Hash 函数 numHashFunctions 。
@VisibleForTesting
static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy) {
checkNotNull(funnel);
checkArgument(
expectedInsertions >= 0, "Expected insertions (%s) must be >= 0", expectedInsertions);
checkArgument(fpp > 0.0, "False positive probability (%s) must be > 0.0", fpp);
checkArgument(fpp < 1.0, "False positive probability (%s) must be < 1.0", fpp);
checkNotNull(strategy);
if (expectedInsertions == 0) {
expectedInsertions = 1;
}
/*
* TODO(user): Put a warning in the javadoc about tiny fpp values, since the resulting size
* is proportional to -log(p), but there is not much of a point after all, e.g.
* optimalM(1000, 0.0000000000000001) = 76680 which is less than 10kb. Who cares!
*/
long numBits = optimalNumOfBits(expectedInsertions, fpp);
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
try {
return new BloomFilter<T>(new LockFreeBitArray(numBits), numHashFunctions, funnel, strategy);
} catch (IllegalArgumentException e) {
throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", e);
}
}
put有不同的策略,如MURMUR128_MITZ_64()策略根据 murmur3_128 方法的到一个 128 位长度的 byte[]。分别取高低 8 位的到两个 hash 值(lowerEight, upperEight)。再根据初始化时的到的执行 hash 的次数进行 hash 运算。
/**
* This strategy uses all 128 bits of {@link Hashing#murmur3_128} when hashing. It looks different
* than the implementation in MURMUR128_MITZ_32 because we're avoiding the multiplication in the
* loop and doing a (much simpler) += hash2. We're also changing the index to a positive number by
* AND'ing with Long.MAX_VALUE instead of flipping the bits.
*/
MURMUR128_MITZ_64() {
@Override
public <T> boolean put(
T object, Funnel<? super T> funnel, int numHashFunctions, LockFreeBitArray bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
boolean bitsChanged = false;
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
// Make the combined hash positive and indexable
bitsChanged |= bits.set((combinedHash & Long.MAX_VALUE) % bitSize);
combinedHash += hash2;
}
return bitsChanged;
}
}
LockFreeBitArray就是真正存放数据的底层数据结构。利用了一个 AtomicLongArray data 来存放数据。所以 set() 时候也是对这个 data 做处理。
/**
* Models a lock-free array of bits.
*
* <p>We use this instead of java.util.BitSet because we need access to the array of longs and we
* need compare-and-swap.
*/
static final class LockFreeBitArray {
private static final int LONG_ADDRESSABLE_BITS = 6;
final AtomicLongArray data;
private final LongAddable bitCount;
LockFreeBitArray(long bits) {
this(new long[Ints.checkedCast(LongMath.divide(bits, 64, RoundingMode.CEILING))]);
}
// Used by serialization
LockFreeBitArray(long[] data) {
checkArgument(data.length > 0, "data length is zero!");
this.data = new AtomicLongArray(data);
this.bitCount = LongAddables.create();
long bitCount = 0;
for (long value : data) {
bitCount += Long.bitCount(value);
}
this.bitCount.add(bitCount);
}
/** Returns true if the bit changed value. */
boolean set(long bitIndex) {
if (get(bitIndex)) {
return false;
}
int longIndex = (int) (bitIndex >>> LONG_ADDRESSABLE_BITS);
long mask = 1L << bitIndex; // only cares about low 6 bits of bitIndex
long oldValue;
long newValue;
do {
oldValue = data.get(longIndex);
newValue = oldValue | mask;
if (oldValue == newValue) {
return false;
}
} while (!data.compareAndSet(longIndex, oldValue, newValue));
// We turned the bit on, so increment bitCount.
bitCount.increment();
return true;
}
}
在 set() 之前先通过 get() 判断这个数据是否存在于集合中,如果已经存在则直接返回告知客户端写入失败。接下来就是通过位运算进行位或赋值。get() 方法的计算逻辑和 set() 类似,只要判断为 0 就直接返回存在该值。