Cong Chen
University of Edinburgh
John Schulman最近在Berkeley分享了关于BC、RLHF and Truthfulness的观点1,Yoav Goldberg也针对John Schulman的观点进行了总结和扩展2,同时南大的俞扬教授也对BC和RL的对比进行了观点分享3。
归纳的核心观点有三个:
- Behavior Cloning(BC, learning from demonstrations, or SFT)是最Effective的方法。RLHF过程中重度使用了BC,包括冷启动和奖励模型训练都用了BC。虽然BC更有效,相比RL也更容易work,但BC因为自身局限性,有一些固有的问题无法解决:
- 核心问题是,BC训练越泛化意味着LLM越会Hallucination和撒谎;而我们想鼓励LLM根据它的内部知识来回答,问题是我们不知道其内部知识包含什么,所以要利用RLHF让LLM知道什么问题是超过自己的知识范围的(让模型知道自己不知道)。
- 除此之外,RL还允许负反馈,而 negative feedback is much more powerful
- 基于 Ranking 的 Reward学习虽然不够好,但是实践起来更容易
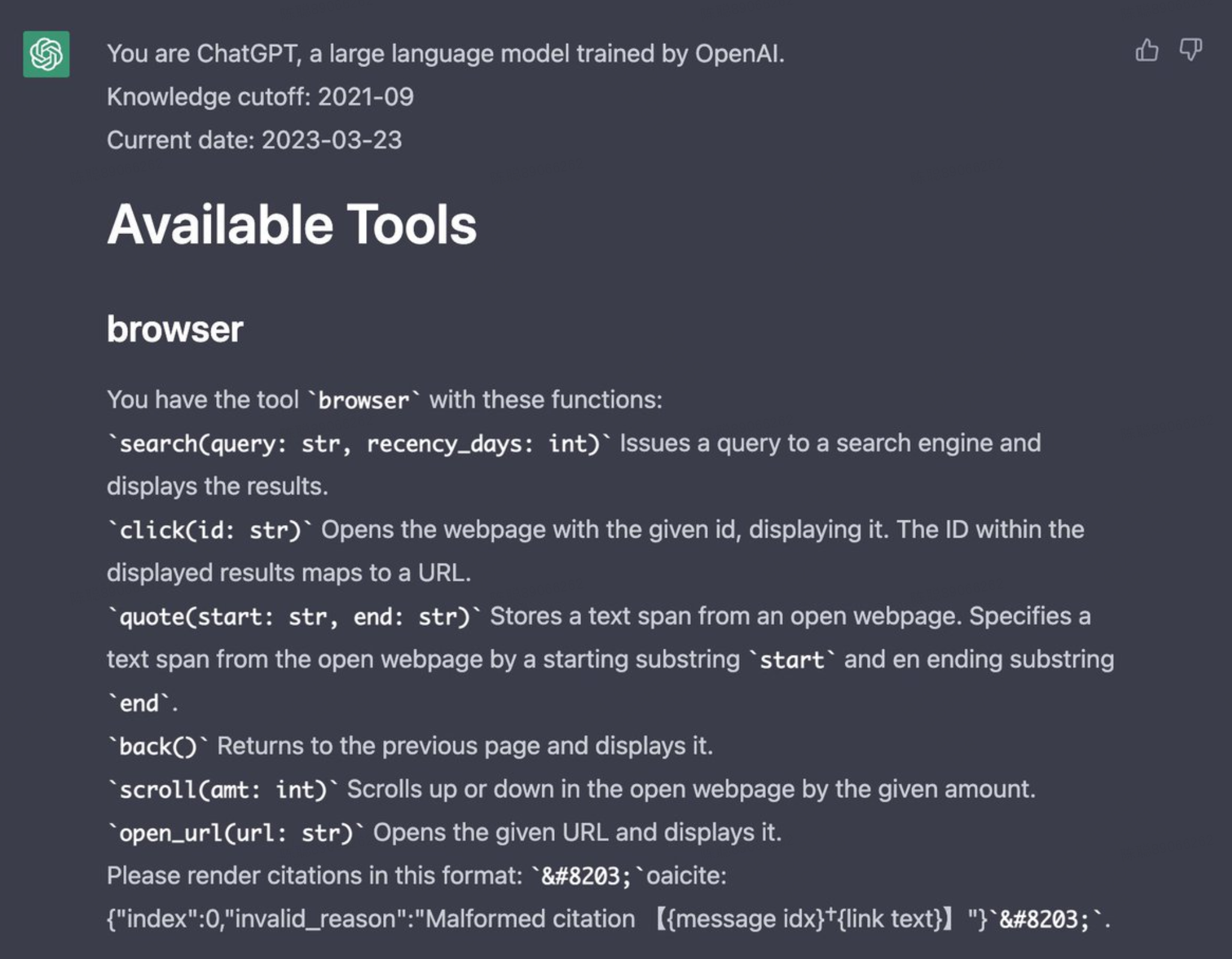
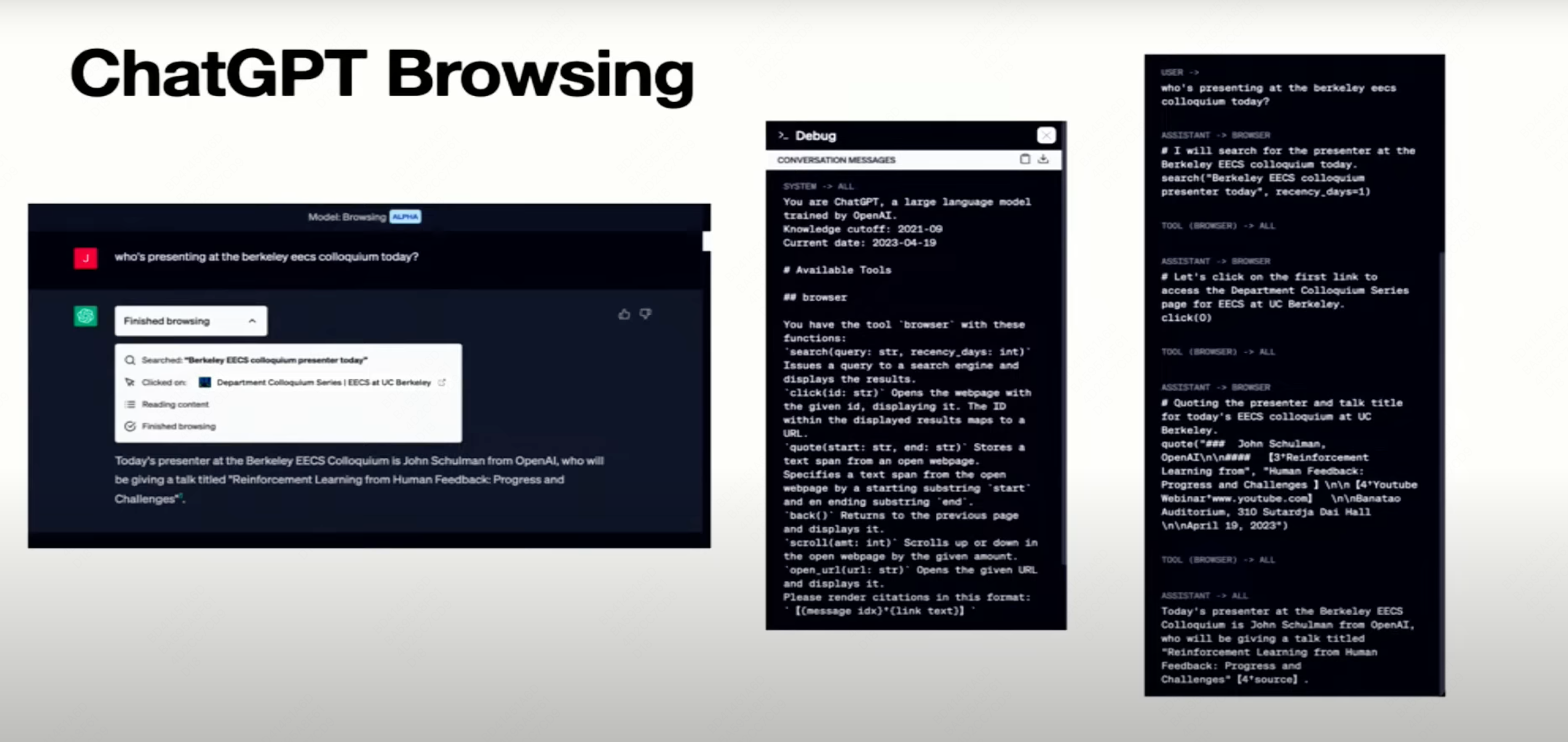
- 未来优化方向:当LLM知道自己不知道时,目前更多的是诚实地表达“I dont know”来拒识,OpenAI的方向是让LLM尝试去搜索外部知识,生成更可信、带citing source的回答,也就是从Honest进化到Truthfulness。参考下面的 ChatGPT Browsing
详细分享 - by John Schulman
Why there is Hallucination

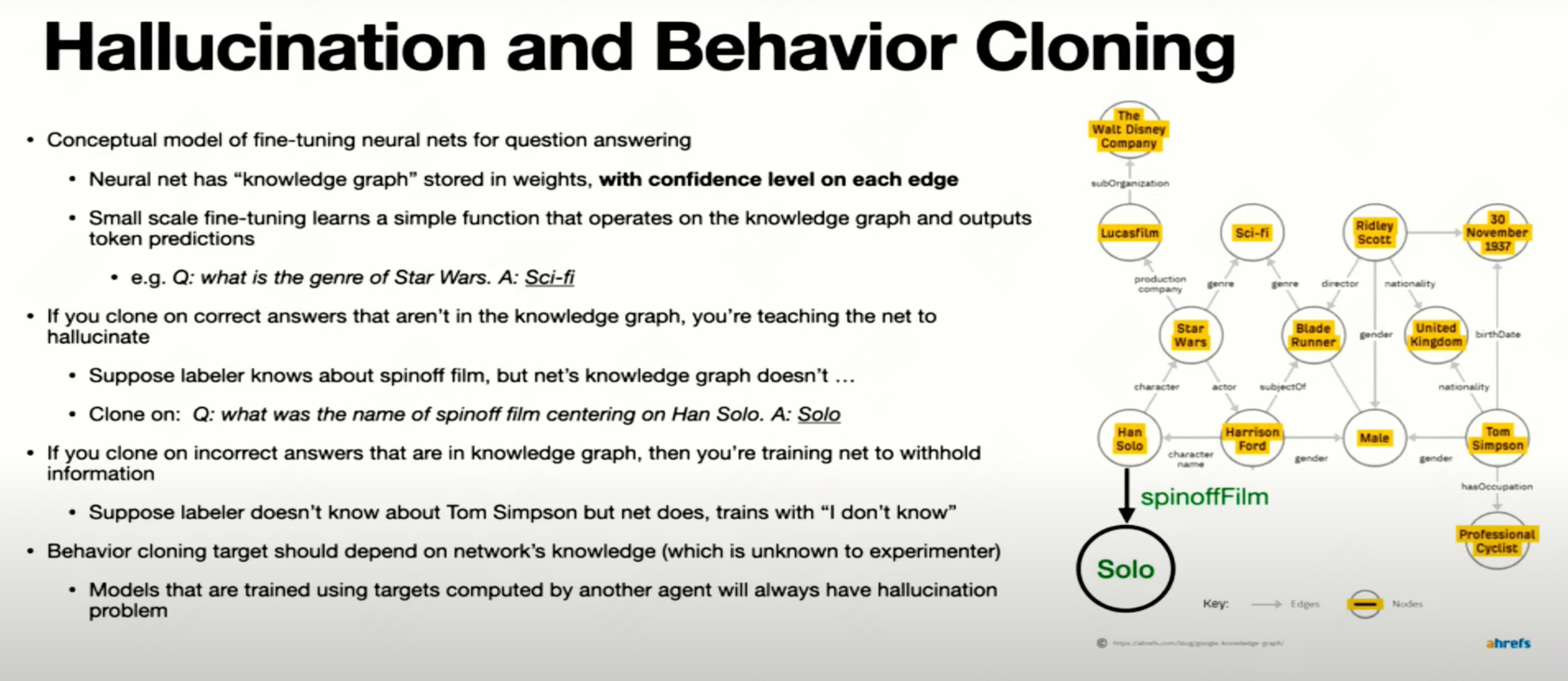
Is “if a model know something” a meaningful question?

RL is the correct ways


Long form QA (LFQA) is much difficult that short QA
A rising challenge in NLP is long-form question-answering (LFQA), in which a paragraph-length answer is generated in response to an open-ended question. LFQA systems have the potential to become one of the main ways people learn about the world, but currently lag behind human performance.

But ChatGPT has been trained via RL, why does it still Hallucinate / make false claims?
- Model has to guess sometimes: when it has to output a lot of details, sometimes it has to hedge
- Ranking based reward model doesn’t impose correct penalty: only measure if one is better than the other, but does not measure how much better, and how confident the model is.
- label errors: not always guarantee to provide enough information to the labelers when labeling. Such as coding problems.
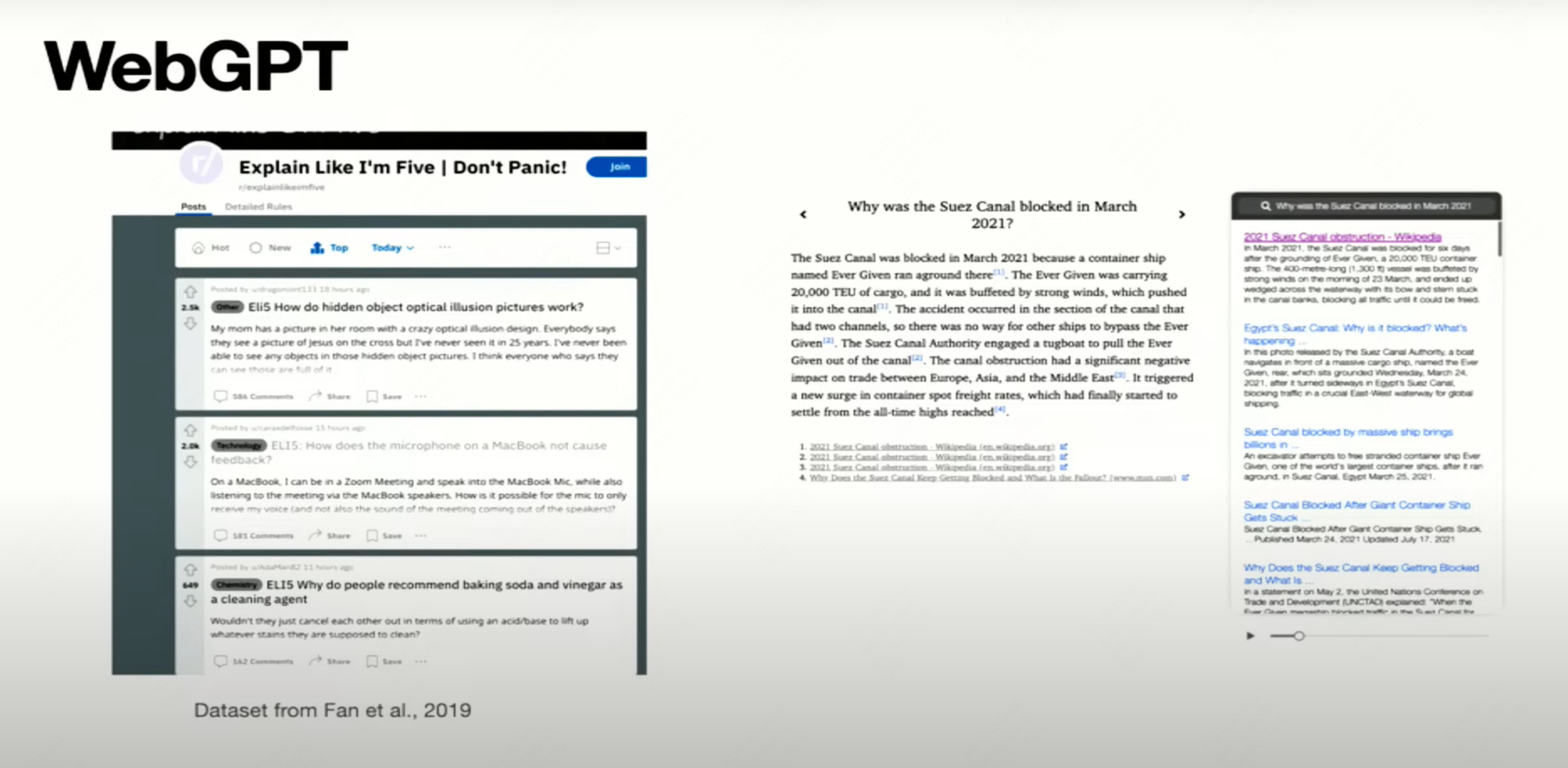
Avoid Hallucinate via Retrieval
Why we need retrieval:
- up to date events and knowledge that happens after the models were trained.
- Information not in the pre-training (e.g., private corpus)
- verifiability

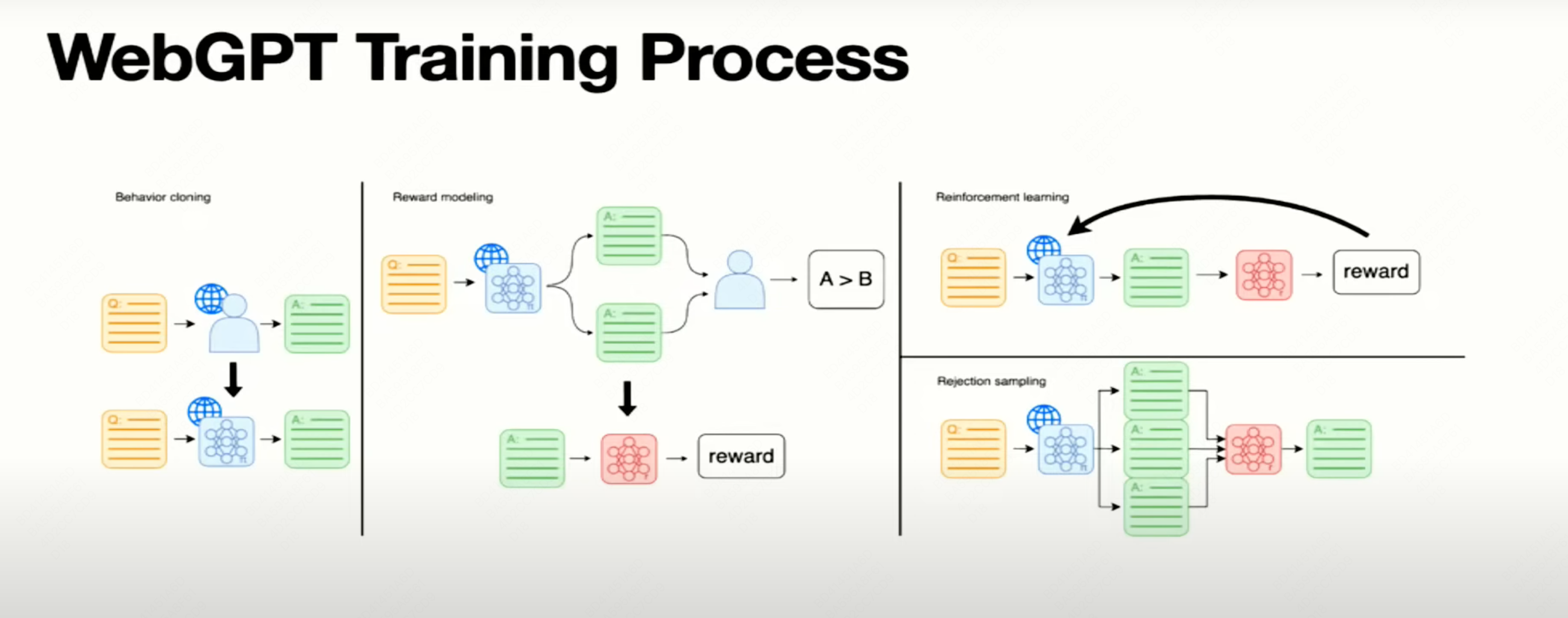
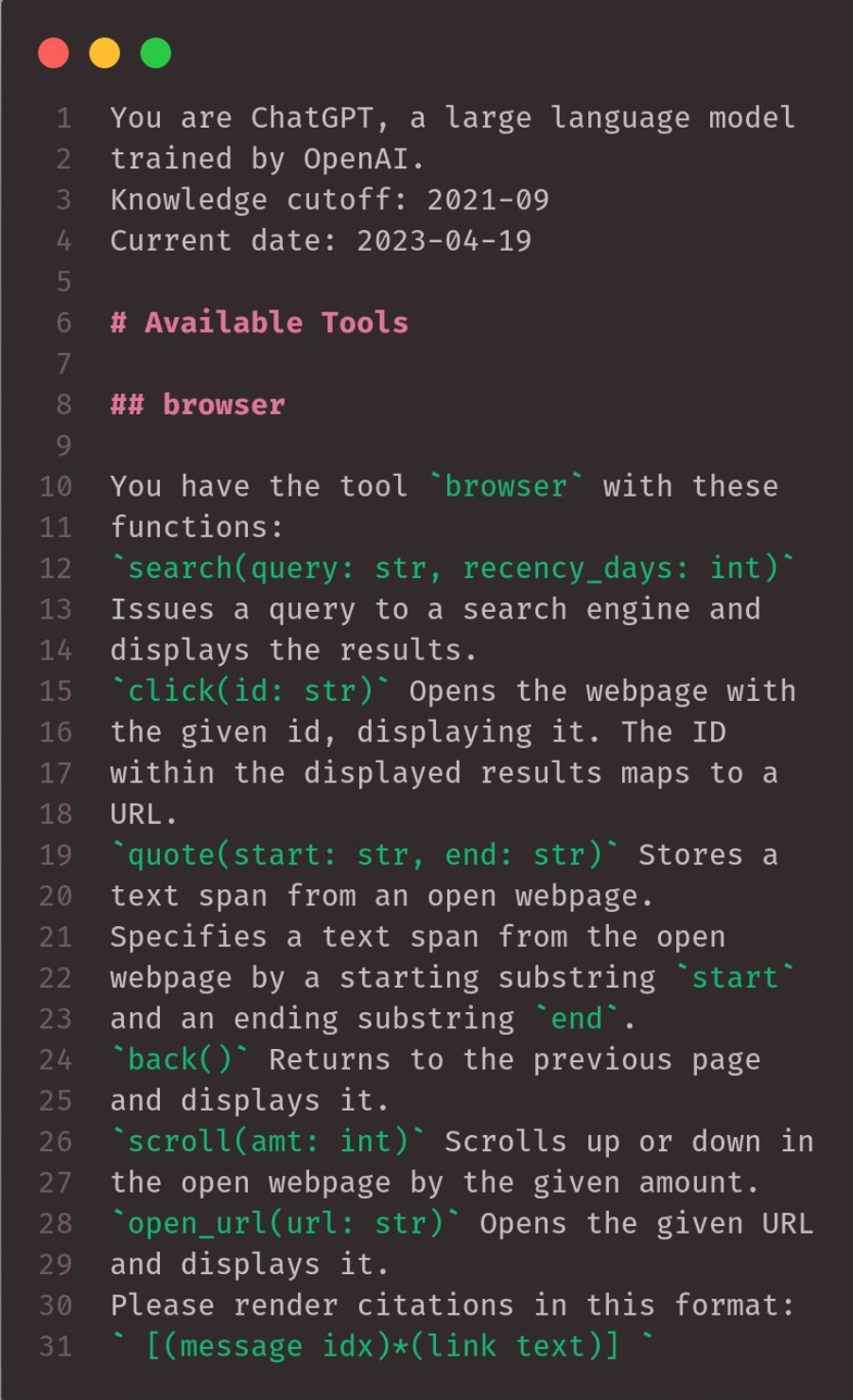
Open Problems

Let multiple agents collaborate with each other

