data: WN18, WN11, FB15K, FB13, FB40K
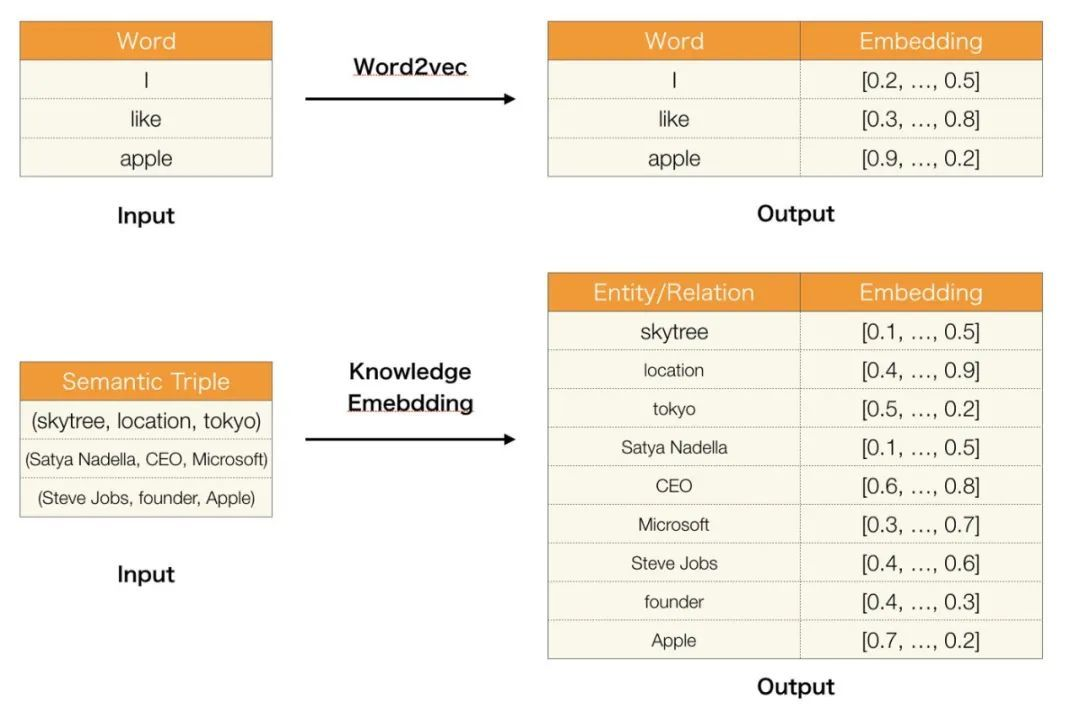
task: Knowledge Graph Embedding
TransE
Translating Embeddings for Modeling Multi-relational Data(2013)
https://proceedings.neurips.cc/paper/2013/file/1cecc7a77928ca8133fa24680a88d2f9-Paper.pdf
这是转换模型系列的第一部作品。该模型的基本思想是使head向量和relation向量的和尽可能靠近tail向量。这里我们用L1或L2范数来衡量它们的靠近程度。
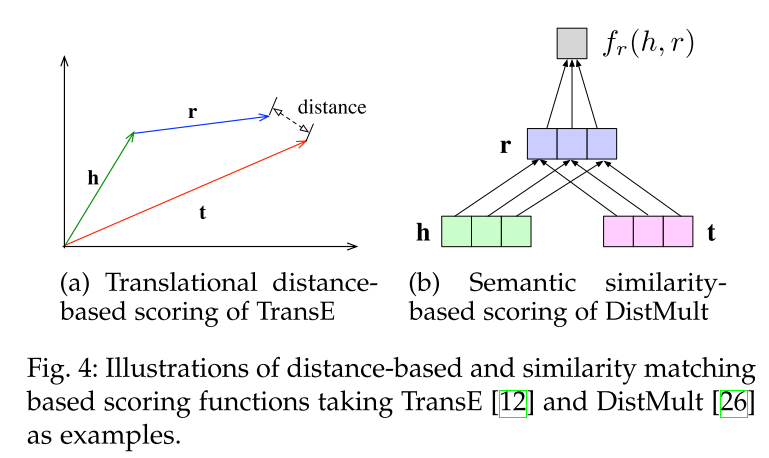

损失函数 $\mathrm{L}(h, r, t)=\max \left(0, d_{\text {pos }}-d_{\text {neg }}+\text { margin }\right)$使损失函数值最小化,当这两个分数之间的差距大于margin的时候就可以了(我们会设置这个值,通常是1)
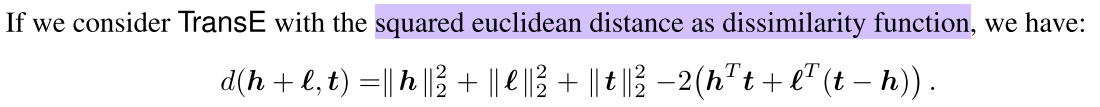
但是这个模型只能处理一对一的关系,不适合一对多/多对一关系,例如,有两个知识,(skytree, location, tokyo)和(gundam, location, tokyo)。经过训练,“sky tree”实体向量将非常接近“gundam”实体向量。但实际上它们没有这样的相似性。
with tf.name_scope("embedding"):
self.ent_embeddings = tf.get_variable(name = "ent_embedding", shape = [entity_total, size], initializer = tf.contrib.layers.xavier_initializer(uniform = False))
self.rel_embeddings = tf.get_variable(name = "rel_embedding", shape = [relation_total, size], initializer = tf.contrib.layers.xavier_initializer(uniform = False))
pos_h_e = tf.nn.embedding_lookup(self.ent_embeddings, self.pos_h)
pos_t_e = tf.nn.embedding_lookup(self.ent_embeddings, self.pos_t)
pos_r_e = tf.nn.embedding_lookup(self.rel_embeddings, self.pos_r)
neg_h_e = tf.nn.embedding_lookup(self.ent_embeddings, self.neg_h)
neg_t_e = tf.nn.embedding_lookup(self.ent_embeddings, self.neg_t)
neg_r_e = tf.nn.embedding_lookup(self.rel_embeddings, self.neg_r)
if config.L1_flag:
pos = tf.reduce_sum(abs(pos_h_e + pos_r_e - pos_t_e), 1, keep_dims = True)
neg = tf.reduce_sum(abs(neg_h_e + neg_r_e - neg_t_e), 1, keep_dims = True)
self.predict = pos
else:
pos = tf.reduce_sum((pos_h_e + pos_r_e - pos_t_e) ** 2, 1, keep_dims = True)
neg = tf.reduce_sum((neg_h_e + neg_r_e - neg_t_e) ** 2, 1, keep_dims = True)
self.predict = pos
with tf.name_scope("output"):
self.loss = tf.reduce_sum(tf.maximum(pos - neg + margin, 0))
TransH
Knowledge Graph Embedding by Translating on Hyperplanes(2014)
TransH的目标是处理一对多/多对一/多对多关系,并且不增加模式的复杂性和训练难度。
其基本思想是将关系解释为超平面上的转换操作。对每个关系r,分配一个超平面的Wr(范数向量), 以及一个在超平面上的translation vector dr, 每个head向量(h)和tail向量(t)投影到超平面上,得到新的向量(h⊥和t⊥)。We expect h⊥ and t⊥ can be connected by a translation vector $d_r$ on the hyperplane with low error if (h, r, t) is a golden triplet ,这样就可以给每个实体只分配一个embedding,同时可以在不同关系上获取不同的投影分量,进行不同的关系表达。可以像TransE模型一样训练它
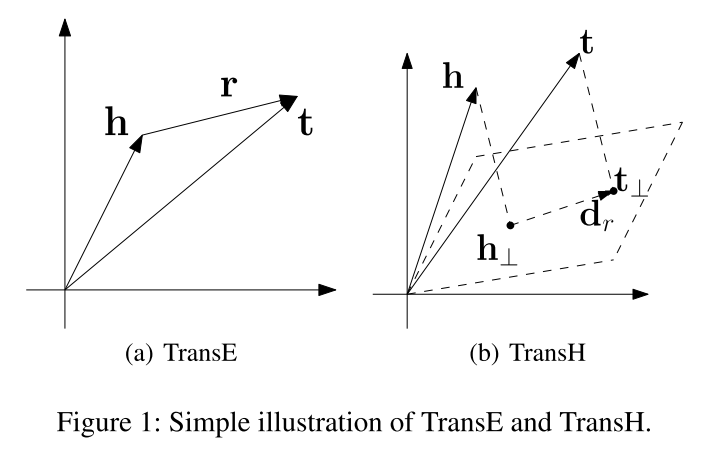
损失函数 $\left\||h{\perp}+d_r - t{\perp}\right\||_2^2$, 限制$||w_r||_2 = 1$

# https://github.com/thunlp/TensorFlow-TransX/blob/42a3c1df34d4c79b88718bdc126552ae59896ca8/transH.py#L31
with tf.name_scope("embedding"):
self.ent_embeddings = tf.get_variable(name = "ent_embedding", shape = [entity_total, size], initializer = tf.contrib.layers.xavier_initializer(uniform = False))
# rel_embeddings: dr
self.rel_embeddings = tf.get_variable(name = "rel_embedding", shape = [relation_total, size], initializer = tf.contrib.layers.xavier_initializer(uniform = False))
# normal_vector: wr
self.normal_vector = tf.get_variable(name = "normal_vector", shape = [relation_total, size], initializer = tf.contrib.layers.xavier_initializer(uniform = False))
pos_h_e = tf.nn.embedding_lookup(self.ent_embeddings, self.pos_h)
pos_t_e = tf.nn.embedding_lookup(self.ent_embeddings, self.pos_t)
pos_r_e = tf.nn.embedding_lookup(self.rel_embeddings, self.pos_r)
neg_h_e = tf.nn.embedding_lookup(self.ent_embeddings, self.neg_h)
neg_t_e = tf.nn.embedding_lookup(self.ent_embeddings, self.neg_t)
neg_r_e = tf.nn.embedding_lookup(self.rel_embeddings, self.neg_r)
pos_norm = tf.nn.embedding_lookup(self.normal_vector, self.pos_r)
neg_norm = tf.nn.embedding_lookup(self.normal_vector, self.neg_r)
pos_h_e = self.calc(pos_h_e, pos_norm)
pos_t_e = self.calc(pos_t_e, pos_norm)
neg_h_e = self.calc(neg_h_e, neg_norm)
neg_t_e = self.calc(neg_t_e, neg_norm)
if config.L1_flag:
pos = tf.reduce_sum(abs(pos_h_e + pos_r_e - pos_t_e), 1, keep_dims = True)
neg = tf.reduce_sum(abs(neg_h_e + neg_r_e - neg_t_e), 1, keep_dims = True)
self.predict = pos
else:
pos = tf.reduce_sum((pos_h_e + pos_r_e - pos_t_e) ** 2, 1, keep_dims = True)
neg = tf.reduce_sum((neg_h_e + neg_r_e - neg_t_e) ** 2, 1, keep_dims = True)
self.predict = pos
with tf.name_scope("output"):
self.loss = tf.reduce_sum(tf.maximum(pos - neg + margin, 0))
def calc(self, e, n):
# cal projections
norm = tf.nn.l2_normalize(n, 1) # ||wr||2 = 1
return e - tf.reduce_sum(e * norm, 1, keep_dims = True) * norm
TransR
Learning Entity and Relation Embeddings for Knowledge Graph Completion(2015)
TransE和TransH模型都假设实体和关系是语义空间中的向量,因此相似的实体在同一实体空间中会非常接近。
然而,每个实体可以有许多方面,不同的关系关注实体的不同方面。例如,(location, contains, location)的关系是’contains’,(person, born, date)的关系是’born’。这两种关系非常不同。
Models entities and relations in distinct spaces, i.e., entity space and multiple relation spaces (i.e., relation-specific entity spaces), and performs translation in the corresponding relation space, 即实体空间和多个关系空间(关系特定的实体空间)中建模实体和关系,并在对应的关系空间中进行转换。
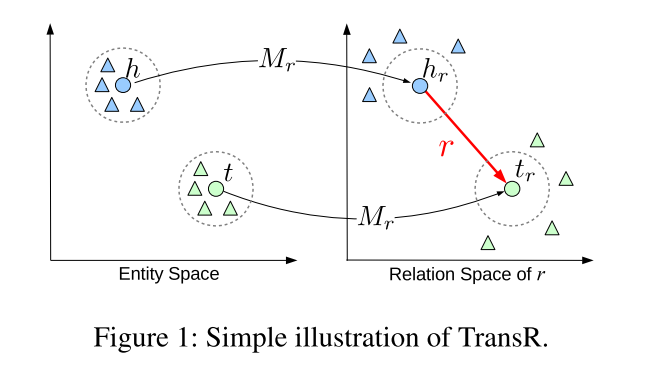

对于每个三元组(h, r, t),将实体空间中的实体通过矩阵Mr投影到r关系空间中,分别为hr和tr,然后有hr + r ≈ tr,损失函数和训练方法与TransE相同。h和t为实体嵌入,r为关系嵌入

Cluster-based TransR (CTransR)
TransR的变体模型称为CTransR, C表示聚类。head和tail实体通常呈现不同的模式。仅仅构建一个关系向量来执行从head到tail实体的所有转换是不够的。例如,三元组(location, contains, location)具有许多模式,如country-city、country-university、contin- country等等。为了解决这个问题,CTransR将不同的head和tail实体对进行聚类,并对每一组学习不同的关系向量。
构造CtransR的过程是,
- 对于一个特定的关系r,将训练数据中所有的实体对(h, t)聚类到多个组中,期望每组中的实体对呈现相似的r关系。
- 使用向量偏移量$(h-t)$表示实体对(h, t)。
- 从TransE得到h和t。
- 为每个聚类学习对应的关系向量$r_c$,为每个关系学习对应的矩阵Mr。

创建负样本时,只替换了head或tail,而不是relation。得到两个变换矩阵分别用于正样本和负样本。除了先用矩阵变换对实体向量进行转换然后计算L2范数外,其余代码基本上与TransE相同。
with tf.name_scope('lookup_embeddings'):
pos_h_e = tf.reshape(tf.nn.embedding_lookup(self.ent_embeddings, self.pos_h), [-1, sizeE, 1])
pos_t_e = tf.reshape(tf.nn.embedding_lookup(self.ent_embeddings, self.pos_t), [-1, sizeE, 1])
pos_r_e = tf.reshape(tf.nn.embedding_lookup(self.rel_embeddings, self.pos_r), [-1, sizeR])
neg_h_e = tf.reshape(tf.nn.embedding_lookup(self.ent_embeddings, self.neg_h), [-1, sizeE, 1])
neg_t_e = tf.reshape(tf.nn.embedding_lookup(self.ent_embeddings, self.neg_t), [-1, sizeE, 1])
neg_r_e = tf.reshape(tf.nn.embedding_lookup(self.rel_embeddings, self.neg_r), [-1, sizeR])
pos_matrix = tf.reshape(tf.nn.embedding_lookup(self.rel_matrix, self.pos_r), [-1, sizeR, sizeE])
neg_matrix = tf.reshape(tf.nn.embedding_lookup(self.rel_matrix, self.neg_r), [-1, sizeR, sizeE])
pos_h_e = tf.nn.l2_normalize(tf.reshape(tf.matmul(pos_matrix, pos_h_e), [-1, sizeR]), 1)
pos_t_e = tf.nn.l2_normalize(tf.reshape(tf.matmul(pos_matrix, pos_t_e), [-1, sizeR]), 1)
neg_h_e = tf.nn.l2_normalize(tf.reshape(tf.matmul(neg_matrix, neg_h_e), [-1, sizeR]), 1)
neg_t_e = tf.nn.l2_normalize(tf.reshape(tf.matmul(neg_matrix, neg_t_e), [-1, sizeR]), 1)
if config.L1_flag:
pos = tf.reduce_sum(abs(pos_h_e + pos_r_e - pos_t_e), 1, keep_dims = True)
neg = tf.reduce_sum(abs(neg_h_e + neg_r_e - neg_t_e), 1, keep_dims = True)
self.predict = pos
else:
pos = tf.reduce_sum((pos_h_e + pos_r_e - pos_t_e) ** 2, 1, keep_dims = True)
neg = tf.reduce_sum((neg_h_e + neg_r_e - neg_t_e) ** 2, 1, keep_dims = True)
self.predict = pos
with tf.name_scope("output"):
self.loss = tf.reduce_sum(tf.maximum(pos - neg + margin, 0))
TransD
Knowledge Graph Embedding via Dynamic Mapping Matrix(2015)
TransR也有其不足之处。
- 首先,head和tail使用相同的转换矩阵将自己投射到超平面上,但是head和tail通常是一个不同的实体,例如,
(Bill Gates, founder, Microsoft)。‘Bill Gate’是一个人,‘Microsoft’是一个公司,这是两个不同的类别。所以他们应该以不同的方式进行转换。 - 第二,这个投影与实体和关系有关,但投影矩阵仅由关系决定。
- 最后,TransR的参数数大于TransE和TransH。由于其复杂性,TransR/CTransR难以应用于大规模知识图谱。
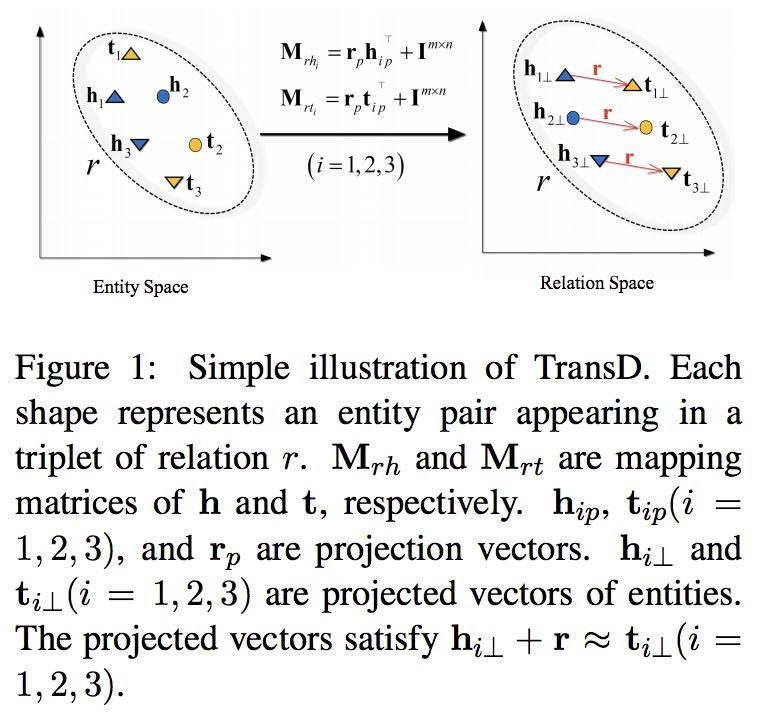
TransD使用两个向量来表示每个实体和关系。第一个向量表示实体或关系的意义,另一个向量(称为投影向量)将用于构造映射矩阵。given a triplet (h, r, t), its vectors are h, hp, r, rp, t, tp, where subscript p marks the projection vectors, h, hp, t, tp ∈ Rn

$\begin{aligned} \mathbf{M}{r h} &=\mathbf{r}{p} \mathbf{h}{p}^{\top}+\mathbf{I}^{m \times n} \\\\ \mathbf{M}{r t} &=\mathbf{r}{p} \mathbf{t}{p}^{\top}+\mathbf{I}^{m \times n} \end{aligned}$
其中映射矩阵由实体和关系定义,I为单位矩阵。这个等式意味着我们使用生成的矩阵(由r和h向量)来修改单位矩阵。投射和训练与TransR相同。TransE是向量维数满足m=n且所有投影向量都设为零时变换的一种特殊情况。
with tf.name_scope("embedding"):
self.ent_embeddings = tf.get_variable(name = "ent_embedding", shape = [entity_total, size], initializer = tf.contrib.layers.xavier_initializer(uniform = False))
self.rel_embeddings = tf.get_variable(name = "rel_embedding", shape = [relation_total, size], initializer = tf.contrib.layers.xavier_initializer(uniform = False))
self.ent_transfer = tf.get_variable(name = "ent_transfer", shape = [entity_total, size], initializer = tf.contrib.layers.xavier_initializer(uniform = False))
self.rel_transfer = tf.get_variable(name = "rel_transfer", shape = [relation_total, size], initializer = tf.contrib.layers.xavier_initializer(uniform = False))
pos_h_e = tf.nn.embedding_lookup(self.ent_embeddings, self.pos_h)
pos_t_e = tf.nn.embedding_lookup(self.ent_embeddings, self.pos_t)
pos_r_e = tf.nn.embedding_lookup(self.rel_embeddings, self.pos_r)
pos_h_t = tf.nn.embedding_lookup(self.ent_transfer, self.pos_h)
pos_t_t = tf.nn.embedding_lookup(self.ent_transfer, self.pos_t)
pos_r_t = tf.nn.embedding_lookup(self.rel_transfer, self.pos_r)
neg_h_e = tf.nn.embedding_lookup(self.ent_embeddings, self.neg_h)
neg_t_e = tf.nn.embedding_lookup(self.ent_embeddings, self.neg_t)
neg_r_e = tf.nn.embedding_lookup(self.rel_embeddings, self.neg_r)
neg_h_t = tf.nn.embedding_lookup(self.ent_transfer, self.neg_h)
neg_t_t = tf.nn.embedding_lookup(self.ent_transfer, self.neg_t)
neg_r_t = tf.nn.embedding_lookup(self.rel_transfer, self.neg_r)
pos_h_e = self.calc(pos_h_e, pos_h_t, pos_r_t)
pos_t_e = self.calc(pos_t_e, pos_t_t, pos_r_t)
neg_h_e = self.calc(neg_h_e, neg_h_t, neg_r_t)
neg_t_e = self.calc(neg_t_e, neg_t_t, neg_r_t)
if config.L1_flag:
pos = tf.reduce_sum(abs(pos_h_e + pos_r_e - pos_t_e), 1, keep_dims = True)
neg = tf.reduce_sum(abs(neg_h_e + neg_r_e - neg_t_e), 1, keep_dims = True)
self.predict = pos
else:
pos = tf.reduce_sum((pos_h_e + pos_r_e - pos_t_e) ** 2, 1, keep_dims = True)
neg = tf.reduce_sum((neg_h_e + neg_r_e - neg_t_e) ** 2, 1, keep_dims = True)
self.predict = pos
with tf.name_scope("output"):
self.loss = tf.reduce_sum(tf.maximum(pos - neg + margin, 0))
def calc(self, e, t, r):
return tf.nn.l2_normalize(e + tf.reduce_sum(e * t, 1, keep_dims = True) * r, 1)
Summary


Reference
- Translating embeddings for modeling multi-relational data
- https://www.microsoft.com/en-us/research/publication/knowledge-graph-embedding-by-translating-on-hyperplanes/
- Learning Entity and Relation Embeddings for Knowledge Graph Completion
- Knowledge Graph Embedding via Dynamic Mapping Matrix
- thunlp/TensorFlow-TransX
- thunlp/KB2E
- Summary of Translate Model for Knowledge Graph Embedding
- 知识图谱嵌入的Translate模型汇总(TransE,TransH,TransR,TransD)