2019, ACL
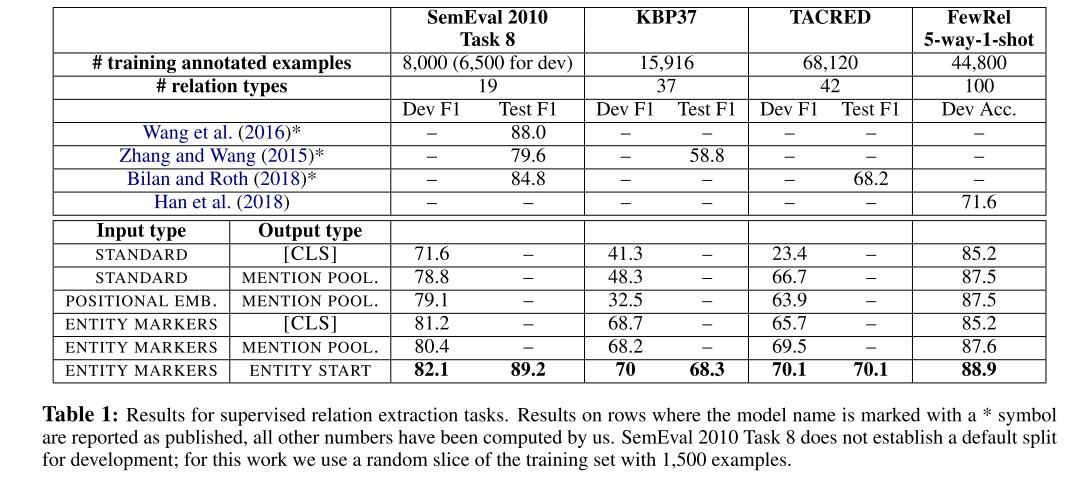
data: KBP37, SemEval 2010 Task 8, TACRED
task: Entity and Relation Extraction
Build task agnostic relation representations solely from entity-linked text.
缺陷
文章认为网页中, 相同的的实体对一般指代相同的实体关系, 把实体不同的构建为负样本. 这个在单份文件中可能大概率是对的.
但是实体不完全一直不代表这个两对实体的关系不同. 所以这个作为负样本是本质上映射的是实体识别而不是关系.
比较好的方式是把实体不同但是关系一样的也考虑进来.
方法
Define Relation Statement
We define a relation statement to be a block of text containing two marked entities. From this, we create training data that contains relation statements in which the entities have been replaced with a special [BLANK]

A relation statement is a triple r = (x, s1, s2), x = [x0 . . . xn] be a sequence of tokens, where x0 = [CLS] and xn = [SEP] are special start and end markers. Let s1 = (i, j) and s2 = (k, l) be pairs of integers such that 0 < i < j −1, j < k, k ≤ l −1, and l ≤ n
learn a function $h_r = f_θ(r)$ that maps the relation statement to a fixed-length vector $h_r ∈ ^Rd$ that represents the relation
Task
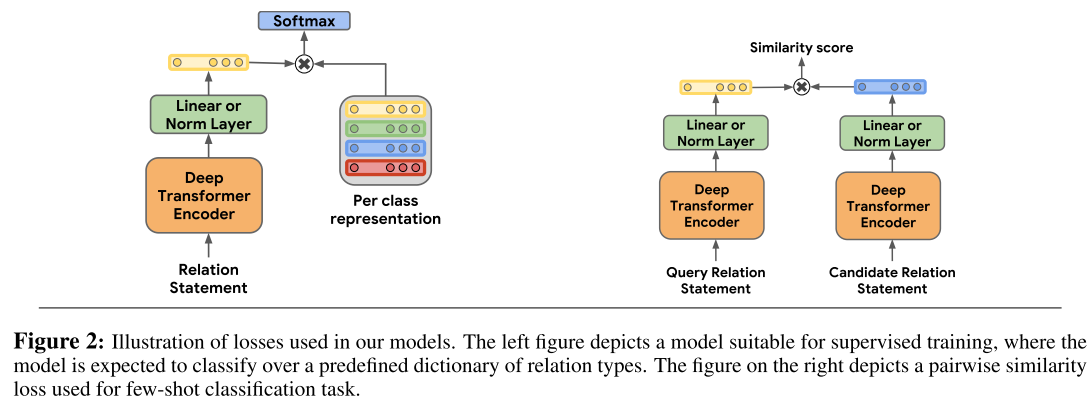
- supervised tasks
- few-shot relation matching: In this task, examples in the test and development sets typically contain relation types not present in the training set.
- we use the dot product between relation representation of the query statement and each of the candidate statements as a similarity score
- we declare that for any pair of relation statements r and r’, the inner product $f_{\theta}(\mathbf{r})^{\top} f_{\theta}\left(\mathbf{r}^{\prime}\right)$ should be high if the two relation statements, express semantically similar relations
- we do not use relation labels at training time, Instead, we observe that there is a high degree of redundancy in web text, and each relation between an arbitrary pair of entities is likely to be stated multiple times. 假设网页文本有大量重复的实体关系提及
Model
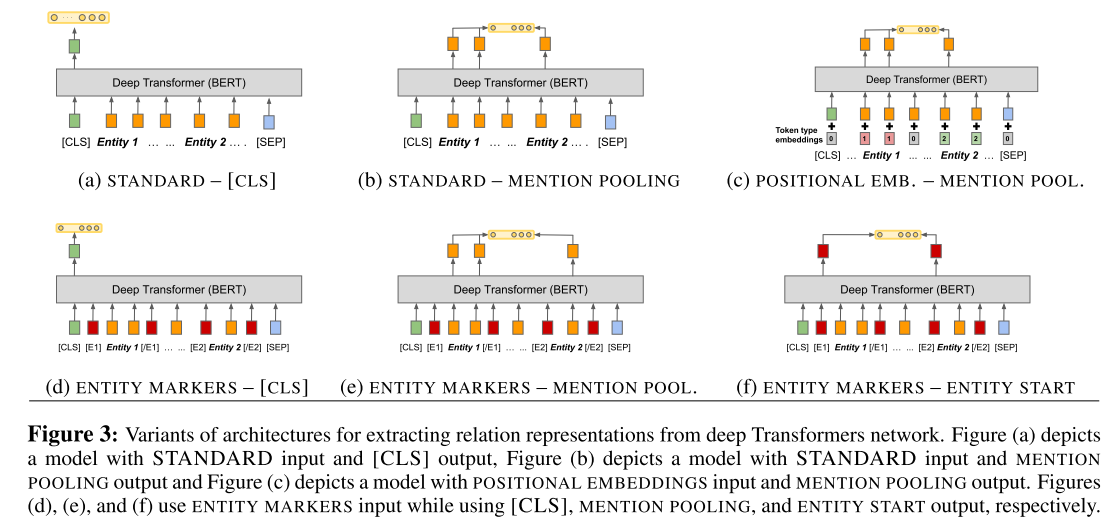
Entity span identification
- Standard input: model that does not have access to any explicit identification of the entity spans
s1ands2 - Positional embeddings: two segmentation embeddings, one that is added to all tokens in the span
s1, while the other is added to all tokens in the spans2 - Entity marker tokens:
[E1start],[E1end][E2start]and[E2end]and modifyxto givex˜ =[x0 . . . [E1start] xi . . . xj−1 [E1end] . . . [E2start] xk . . . xl−1 [E2end] . . . xn].
Fixed length relation representation
[CLS]token- Entity mention pooling: concatenate $h_{e1}= MAXPOOL([h_i...h_{j−1}])$ and $he_{e_2} =MAXPOOL([h_k...h_{l−1}])$
- Entity start state: concatenation of the final hidden states corresponding their respective start tokens
Training
Takes in pairs of blank-containing relation statements, and has an objective that encourages relation representations to be similar if they range over the same pairs of entities.
define binary classifier, learn a relation statement encoder fθ that we can use to determine whether or not two relation statements encode the same relation. minimizes the loss

4.2 Introducing Blanks
To avoid simply relearning the entity linking system, 用[BLANK] symbol 以概率α替换掉 entity in relation statement.
效果
outperform previous work on exemplar based relation extraction (FewRel) even with- out using any of that task’s training data. We also show that models initialized with our task agnostic representations, and then tuned on supervised relation extraction datasets, significantly outperform the previous methods on SemEval 2010 Task 8, KBP37, and TACRED