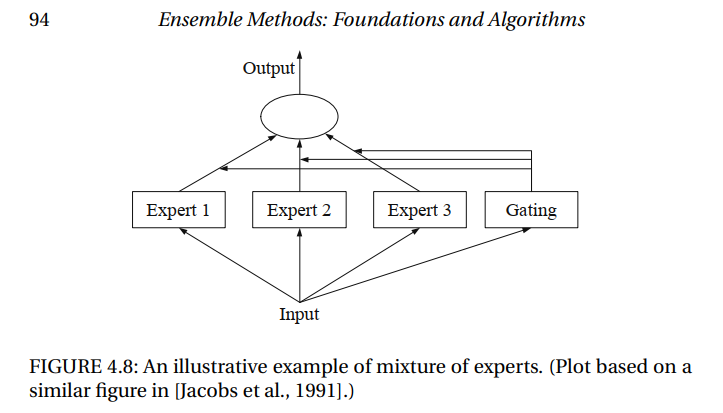
Mixture of Experts (MOE)
MOE属于Ensemble Method中的一个方法, 采用分治思想:
- 将复杂的建模任务分解为多个相对简单的子任务,为每个子任务训练专门的模型:涉及子任务分解,或者Clustering
- 需要一个门控模型,基于数据输入选择如何组合多个专家模型的结果
Mixture of experts aims at increasing the accuracy of a function approximation by replacing a single global model by a weighted sum of local models (experts). It is based on a partition of the problem domain into several subdomains via clustering algorithms followed by a local expert training on each subdomain.
Local Models & Global Models
Hinton的课件介绍了模型拟合分布的两个极端方式:
- Very local models: 使用很多非常局部化的模型, e.g. Nearest neighbors,
- Very fast to fit: Just store training cases
- Local smoothing 提升效果
- Fully global models: 使用一个全局大模型 – e. g. Polynomial
- May be slow to fit: Each parameter depends on all the data
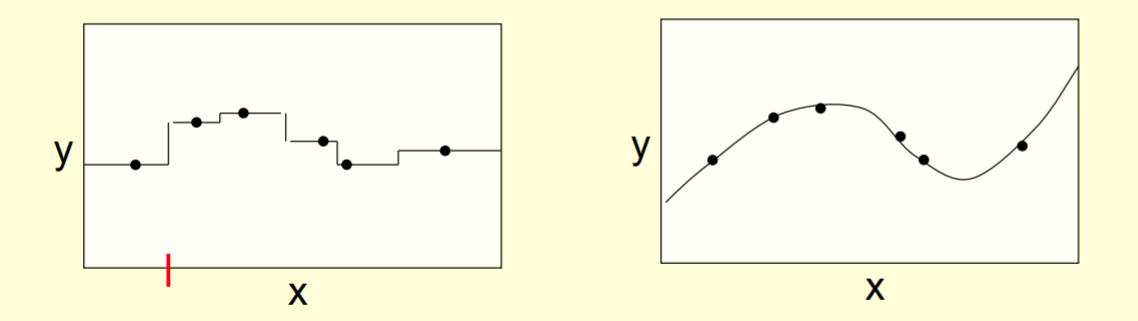
两种极端各有利弊, 不如采取中庸之道, 使用几个中等复杂度的专家模型.
- Good if the dataset contains several different regimes which have different relationships between input and output.
难点在于如何给多个专家模型切分数据. 这里的核心目的不是基于输入分布相似性的 clustering. 而是为基于输入-输出之间的不同关系切分给不同的局部专家模型, 使每个专家模型能够很好的建模它分内的输入-输出关系.
组合结果-MOE
最简单直接的就是平均多个专家模型的结果. 但是平均的缺陷是: If we always average all the predictors, each model is trying to compensate for the combined error made by all the other models.
所以, The key idea is to make each expert focus on predicting the right answer for the cases where it is already doing better than the other experts. 也就是专家的专业化.
通过设计损失函数来鼓励专家模型specialization 而不是 cooperation.
- encourage cooperation: compare the average of all the predictors with the target and train to reduce the discrepancy. $(d - E(y_i))^2$
- encourage specialization: compare each predictor separately with the target and train to reduce the average of all these discrepancies. $E(p_i(d - y_i)^2)$, $p_i$ is probability of picking expert i for this case
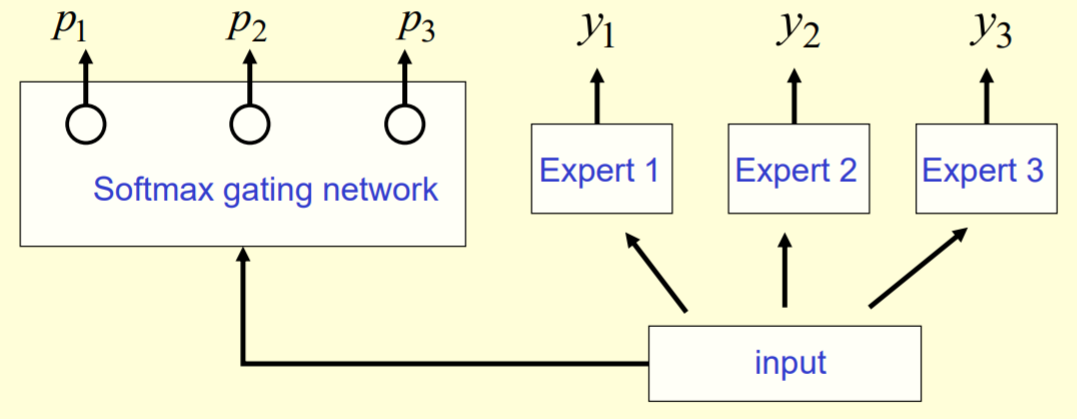
组合预测结果: take a weighted average, using the gating network to decide how much weight to place on each expert. $y = \sum_i p_i y_i$
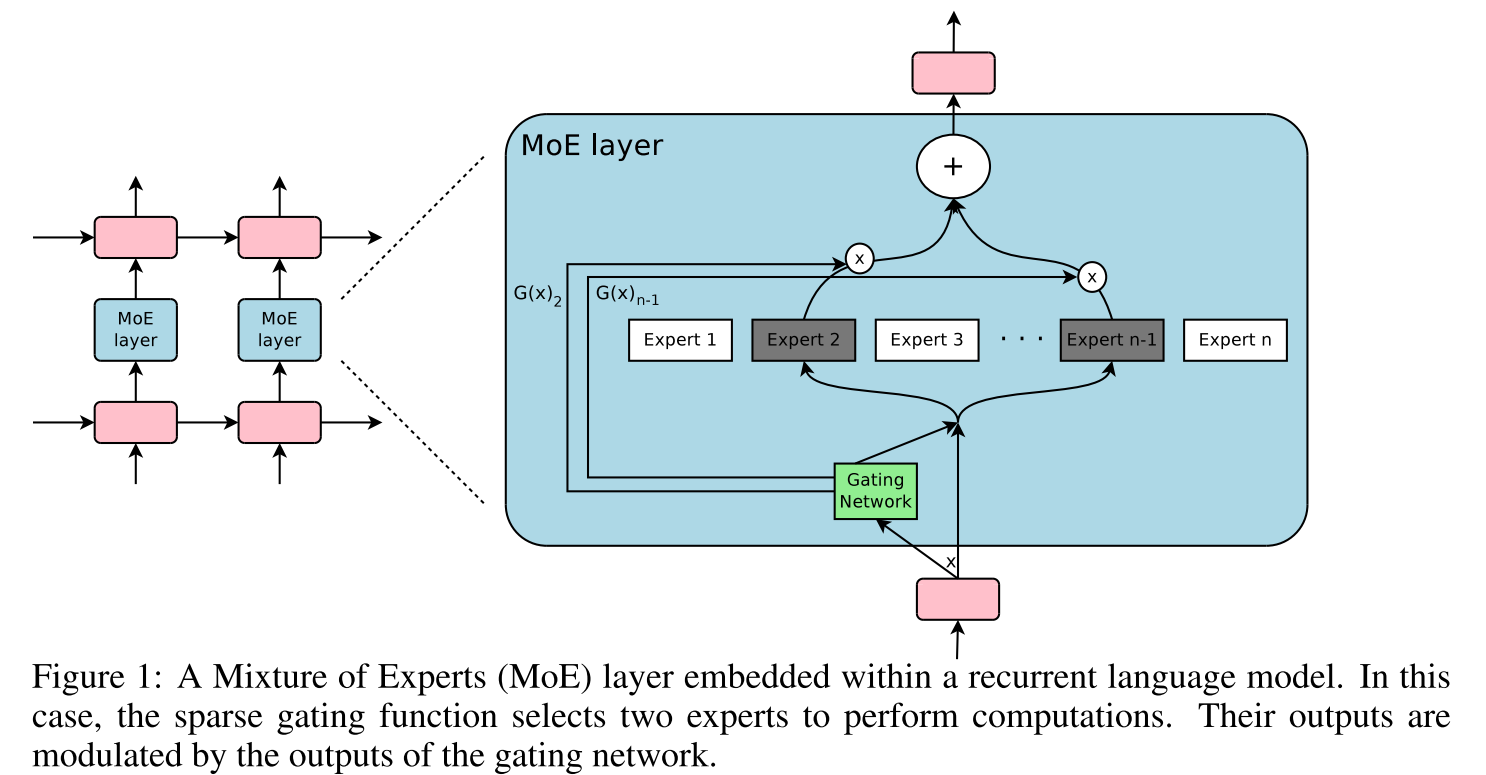
Sparsely-Gated Mixture-of-Experts layer (MoE)
基于Conditional computation的思想,Outrageously large neural networks: The sparsely-gated mixture-of-experts layer利用MOE搭建了包含thousands of feed-forward sub-networks(experts)的网络架构,利用可训练的门控网络来针对不同样本决策不同的experts稀疏组合,构建了up to 137 billion parameters is applied convolutionally between stacked LSTM layers,在large language modeling and machine translation benchmarks上取得sota。
Conditional Computation(CC)
Conditional computation, where parts of the network are active on a per-example basis, has been proposed in theory as a way of dramatically increasing model capacity without a proportional increase in computation.
Conditional Computation的困难在于:
- GPU are much faster at arithmetic than at branching.
- Conditional Computation会减少活跃网络的batch size,而当前深度学习往往受益于更大的batch size
- 网络通信是瓶颈。因为GPU集群的计算能力往往是设备通信能力的几千倍,所以评估一个模型算法的效率,一个很有效的标准就是这个计算量和通信量的比率。Embedding 层就是一种典型Conditional computation。Embedding的计算量不大,但是不同设备的模型需要实时共享embedding参数,所以效率并不高。
门控网络
Softmax Gating: non-sparse gating function (Jordan & Jacobs, 1994)
$$G_σ(x) = Softmax(x · W_g)$$Noisy Top-K Gating: add sparsity and noise to softmax gating, we add tunable Gaussian noise, then keep only the top k values. The noise term helps with load balancing.

虽然这种稀疏性理论上有很明显的不连续性质,但是实践中并没带来什么问题。
While this form of sparsity creates some theoretically scary discontinuities in the output of gating function, we have not yet observed this to be a problem in practice
Switch Transformers
近来超大规模Transformers模型的一个发展方向就是利用Mixture of experts (MOE)把大模型的FFN结构部分改为多个sparse Switch FFN layer的组合,以此来达成模型的扩容。
Reference
- CSC321: Introduction to Neural Networks and Machine Learning, Lecture 15: Mixtures of Experts, Geoffrey Hinton https://www.cs.toronto.edu/~hinton/csc321/notes/lec15.pdf
- Outrageously large neural networks: The sparsely-gated mixture-of-experts layer
- SWITCH TRANSFORMERS: SCALING TO TRILLION PARAMETER MODELS WITH SIMPLE AND EFFICIENT SPARSITY