Multi-token prediction vs Next-token prediction
Next-token prediction is the standard training objective for most large language models (LLMs), where the model learns to predict the subsequent token in a sequence given all preceding tokens. The model is trained to maximize the probability of the next token \( x_{t+1} \) given the context \( x_{1:t} \) (all tokens up to position \( t \)).
The cross-entropy loss for next-token prediction is defined as:
where \( P_\theta \) is the model parameterized by \( \theta \), and \( x_{1:t} \) denotes the sequence of tokens from position 1 to \( t \).
The model is trained in an autoregressive manner, where each prediction relies solely on the ground-truth history of tokens, not on its own prior predictions (teacher forcing).
The core idea of Multi-token prediction (MTP) (Gloeckle, Fabian, et al. Better & Faster Large Language Models via Multi-Token Prediction. arXiv:2404.19737, arXiv, 30 Apr. 2024. arXiv.org, https://doi.org/10.48550/arXiv.2404.19737.) is to enable the model to predict multiple future tokens simultaneously at each position in the training corpus, which improves sample efficiency and inference speed.
Comparison Between Next-Token Prediction and Multi-Token Prediction
| Aspect | Next-Token Prediction | Multi-Token Prediction (MTP) in the Papers |
|---|---|---|
| Prediction Scope | Single future token | \( n \) future tokens simultaneously (e.g., \( n=4 \)) |
| Training Efficiency | Requires more data due to local focus | Improves sample efficiency by capturing long-term dependencies |
| Inference Speed | Sequential decoding (slow for long sequences) | Speculative decoding via extra heads (3× faster in Gloeckle et al., 1.8× TPS in DeepSeek-V3) |
| Architectural Cost | Simple single head | Additional heads but with minimal overhead (sequential computation in Gloeckle et al., shared modules in DeepSeek-V3) |
Multi-token prediction
Gloeckle et al. argue that next-token prediction is inefficient because it focuses on local patterns and overlooks long-term dependencies. This requires significantly more training data compared to human learning (e.g., children learn language with far fewer examples). During inference, the model must generate tokens autoregressively (using its own prior predictions), while training uses ground-truth tokens. This creates a gap between training and inference, leading to error accumulation.
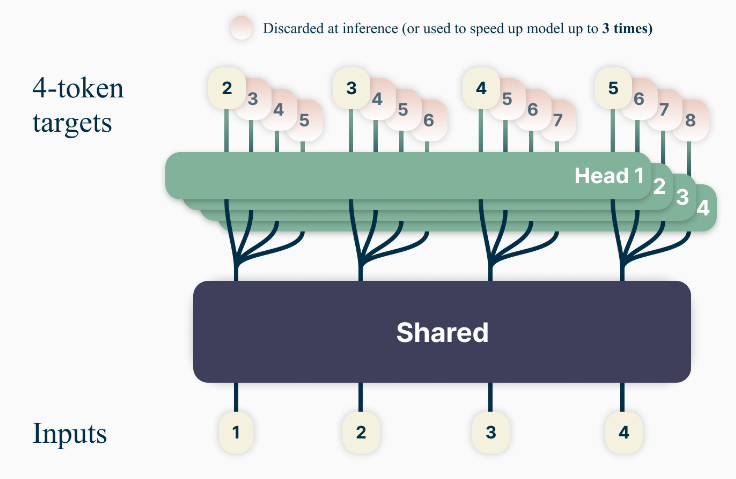
During training, for any time step t:
- The model uses a shared transformer trunk to generate a latent representation \( z_{t:1} \) from the context \( x_{t:1} \) (all tokens up to position \( t \)). This latent representation is then fed into \( n \) independent output heads, each dedicated to predicting a specific future token \( x_{t+i} \) for \( i = 1, \dots, n \), in parallel. More specifically, the model’s heads for predicting tokens at positions \( t+k \) (where \( k > 1 \)) do not rely on previous predicted tokens (e.g., \( t+1 \)) during training. This design avoids additional training overhead by sequentially computing forward/backward passes for each head, reducing peak GPU memory usage from \(O(nV + d)\) to \(O(V + d)\). For example, to predict tokens at \( t+1, t+2, t+3, t+4 \), each head \( i \) directly uses \( z_{t:1} \) to generate \( P_\theta(x_{t+i} | x_{t:1}) \), without using the output of head \( i-1 \) (which predicts \( x_{t+i-1} \)). For the sequence
Hi, I would like _t1, _t2, _t3, _t4, the prediction of \( _t2 \) ( \( t+2 \)) is based onHi, I would like( \( x_{t:1} \) where \( t \) is the position before \( _t1 \)), not on the predicted \( _t1 \). The model is trained to predict \( _t1, _t2, _t3, _t4 \) in parallel, each relying solely on the initial context, not on a chain of prior predictions. Unlike autoregressive decoding (where each step uses the previous token’s prediction), MTP during training is non-causal for future tokens—each head looks directly at the original context to predict its target token, avoiding dependency on intermediate predictions. This design enables parallel training and faster inference via speculative decoding. This is explicitly stated in the paper’s formula:
\[ P_\theta(x_{t+i} | x_{t:1}) = \text{softmax}(f_u(f_{h_i}(f_s(x_{t:1}))) \]
where \( f_s \) is the shared trunk, \( f_{h_i} \) is the \( i \)-th head, and \( f_u \) is the unembedding matrix. Each head \( f_{h_i} \) operates independently on \( f_s(x_{t:1}) \), not on previous heads’ outputs. - The loss function aggregates predictions for \( n \) future tokens simultaneously, but each prediction is conditioned only on the original context \( x_{t:1} \), not on intermediate predictions: \[ L_n = -\sum_t \log P_\theta(x_{t+n:t+1} | x_{t:1}) \] This encourages the model to learn longer-term dependencies and mitigates the distribution mismatch between teacher-forced training and autoregressive inference.

During inference, only the next-token output head is employed. Optionally, the other extra heads enable self-speculative decoding, where the model pre-emptively predicts multiple tokens to skip redundant computations. This achieves up to 3× faster inference on code tasks with large batch sizes.
On code benchmarks like HumanEval and MBPP, 13B-parameter models with 4-token prediction solved 12% and 17% more problems, respectively, compared to next-token baselines. The approach also improved algorithmic reasoning and induction capabilities in synthetic tasks.
Comparison with Multi-Token Prediction in DeepSeek-V3
DeepSeek-V3(DeepSeek-AI, et al. DeepSeek-V3 Technical Report. arXiv:2412.19437, arXiv, 27 Dec. 2024. arXiv.org, https://doi.org/10.48550/arXiv.2412.19437. ) notes that next-token prediction encourages the model to prioritize short-term dependencies, which may hinder its ability to learn global structures or complex reasoning tasks (e.g., coding, math). DeepSeek-V3 also employs MTP but with distinct architectural and operational differences:
- Architectural Implementation
- Gloeckle et al.: Parallel independent heads for simultaneous prediction of \(n\) tokens, with each head operating on the shared trunk’s output. Example: 4-token prediction uses 4 separate heads.
- DeepSeek-V3: Sequential MTP modules that maintain a causal chain for each prediction depth. Each module \(k\) combines the current token representation with the embedding of the \((i+k)\)-th token, passing through a Transformer block \(TRM_k\) before prediction. This design preserves the dependency chain for deeper context reasoning.
- Training Objective and Loss Function
- Gloeckle et al.: The loss is the average cross-entropy over \(n\) heads, with a fixed weight \(\lambda\) (e.g., \(\lambda = 0.3\) for early training).
- DeepSeek-V3: MTP loss is a weighted average of cross-entropy losses from \(D\) sequential modules, with the weight \(\lambda\) decaying from 0.3 to 0.1 during training. The sequential design allows deeper integration with the model’s causal attention mechanism.
- Memory and Computation Efficiency
- Gloeckle et al.: Optimizes memory via sequential head computation, reducing GPU memory overhead. Training speed remains comparable to baselines.
- DeepSeek-V3: Leverages shared embedding layers and output heads between MTP modules and the main model, further reducing parameter redundancy. The MoE architecture (with 37B activated parameters) combined with MTP enables efficient scaling.
- Inference Acceleration Strategies
- Gloeckle et al.: Self-speculative decoding using extra heads to pre-predict tokens, achieving 3× speedup on code tasks.
- DeepSeek-V3: MTP modules are repurposed for speculative decoding, with an 85–90% acceptance rate for the second predicted token, leading to 1.8× higher tokens per second (TPS). The MoE routing further optimizes communication during decoding.
- Domain Focus and Performance
- Gloeckle et al.: Primarily targets code and math tasks, demonstrating significant gains on HumanEval (12% improvement) and MBPP (17% improvement) for 13B models.
- DeepSeek-V3: MTP complements its MoE architecture to excel across broader domains: code (LiveCodeBench Pass@1: 40.5%), math (MATH-500 EM: 90.2%), and multilingual tasks (MMMLU-non-English: 79.4%). The model outperforms open-source baselines and rivals closed-source models like GPT-4o.
- Integration with Other Techniques
- Gloeckle et al.: MTP is a standalone training objective without auxiliary losses for load balancing.
- DeepSeek-V3: MTP is combined with an auxiliary-loss-free load balancing strategy for MoE, ensuring expert utilization while minimizing performance degradation. This integration enables more stable training for extremely large models.

Key Differences Summary
| Aspect | Gloeckle et al. (2024) | DeepSeek-V3 |
|---|---|---|
| Architecture | Parallel independent heads | Sequential causal modules |
| Prediction Flow | Simultaneous parallel prediction | Sequential prediction with causal chain |
| Integration with MoE | Not applicable (dense model) | Tightly integrated with MoE routing |
| Inference Speedup | 3× via self-speculative decoding | 1.8× TPS with high token acceptance |
| Training Focus | Code/math efficiency | Broad-domain performance + MoE scaling |
| Auxiliary Losses | None (pure MTP) | Combined with load-balancing strategy |
Both approaches leverage MTP to enhance training efficiency and inference speed, but DeepSeek-V3 extends the paradigm by integrating it with MoE architecture and auxiliary techniques, making it suitable for extremely large models with broader task coverage. Gloeckle et al.’s method is simpler and more focused on code/math tasks, demonstrating that MTP alone can drive significant improvements in sample efficiency and reasoning.