Links: https://arxiv.org/abs/2106.07139
最新出炉的 Pre-Trained Models 综述速览。
先确定综述中的一些名词的定义
- Transfer learning:迁移学习,一种用于应对机器学习中的data hungry问题的方法,是有监督的
- Self-Supervised Learning:自监督学习,也用于应对机器学习中的data hungry问题,特别是针对完全没有标注的数据,可以通过某种方式以数据自身为标签进行学习(比如language modeling)。所以和无监督学习有异曲同工之处。
- 一般我们说无监督主要集中于clustering, community discovery, and anomaly detection等模式识别问题
- 而self-supervised learning还是在监督学习的范畴,集中于classification and generation等问题
- Pre-trained models (PTMs) :预训练模型,Pre-training是一种具体的训练方案,可以采用transfer learning或者Self-Supervised Learning方法
2 Background 脉络图谱
Pre-training 可分为两大类:
- 2.1 Transfer Learning and Supervised Pre-Training
- 此类可进一步细分为 feature transfer 和 parameter transfer.
- 2.2 Self-Supervised Learning and Self-Supervised Pre-Training
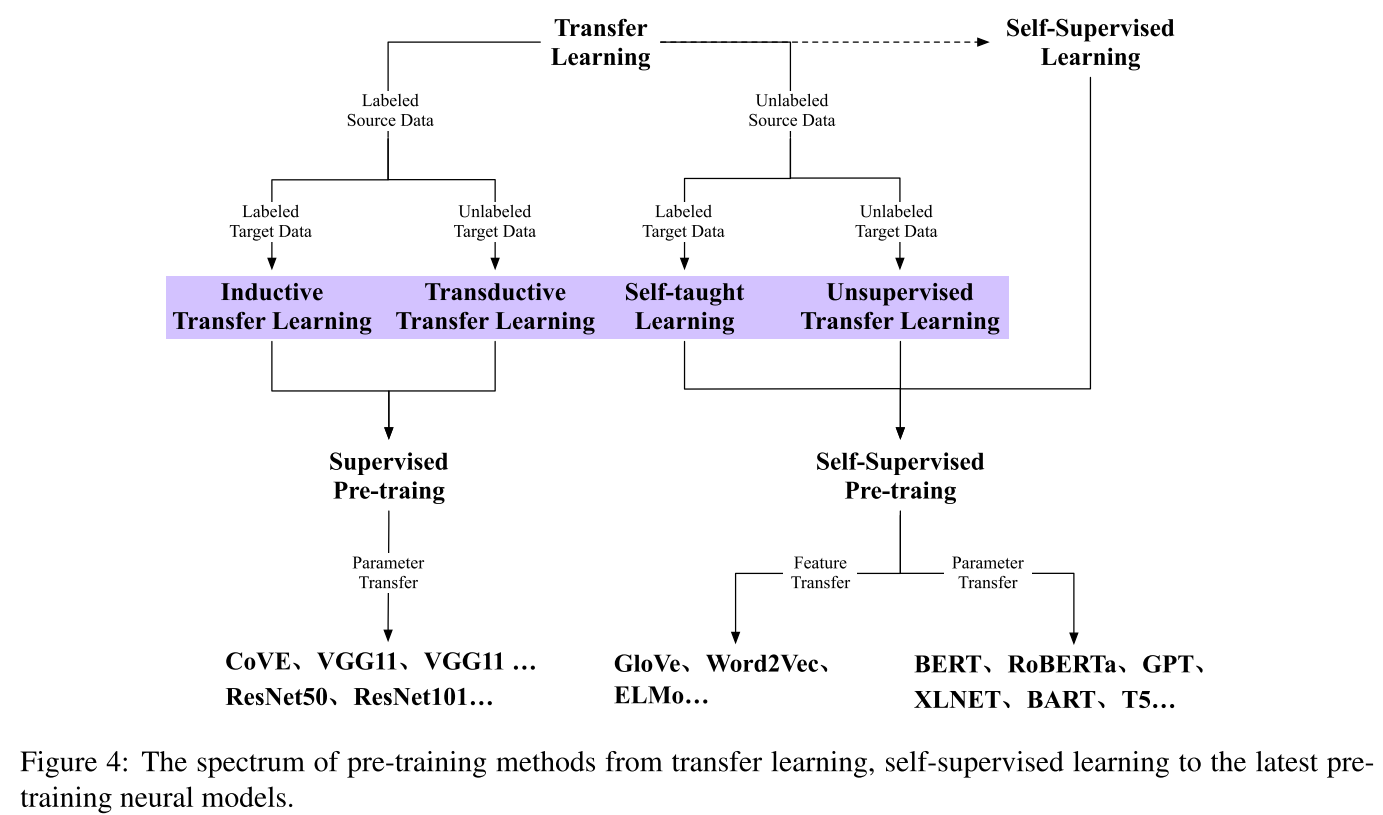
Transfer learning 可细分为四个子类
- inductive transfer learning (Lawrence and Platt, 2004; Mihalkova et al., 2007; Evgeniou and Pontil, 2007),
- transductive transfer learning (Shimodaira, 2000; Zadrozny,2004; Daume III and Marcu, 2006),
- self-taught learning (Raina et al., 2007; Dai et al., 2008)
- unsupervised transfer learning (Wang et al., 2008).
inductive transfer learning 和 transductive transfer learning 的研究进展主要集中以imageNet为labeled source data资源的图像领域
self-taught learning 和 unsupervised transfer learning 则主要集中于NLP领域,由于NLP领域的数据标注难度更大,所以主要以无监督的语言模型训练为主,2013年到2017年主要是词向量这类Feature transfer应用为主,把训练好的词表示作为下游模型的输入,但feature是固定的(ELMO是作为往可修正的feature方向发展的跳板),2018年开始有了BERT和GPT这种基于上下文的表示,把预训练的模型参数迁移到下游任务。
3 Transformer and Representative PTMs
这部分主要介绍基于Transformer的各种表征学习PTMs, 如GPT和BERT,以及后续的家族图谱
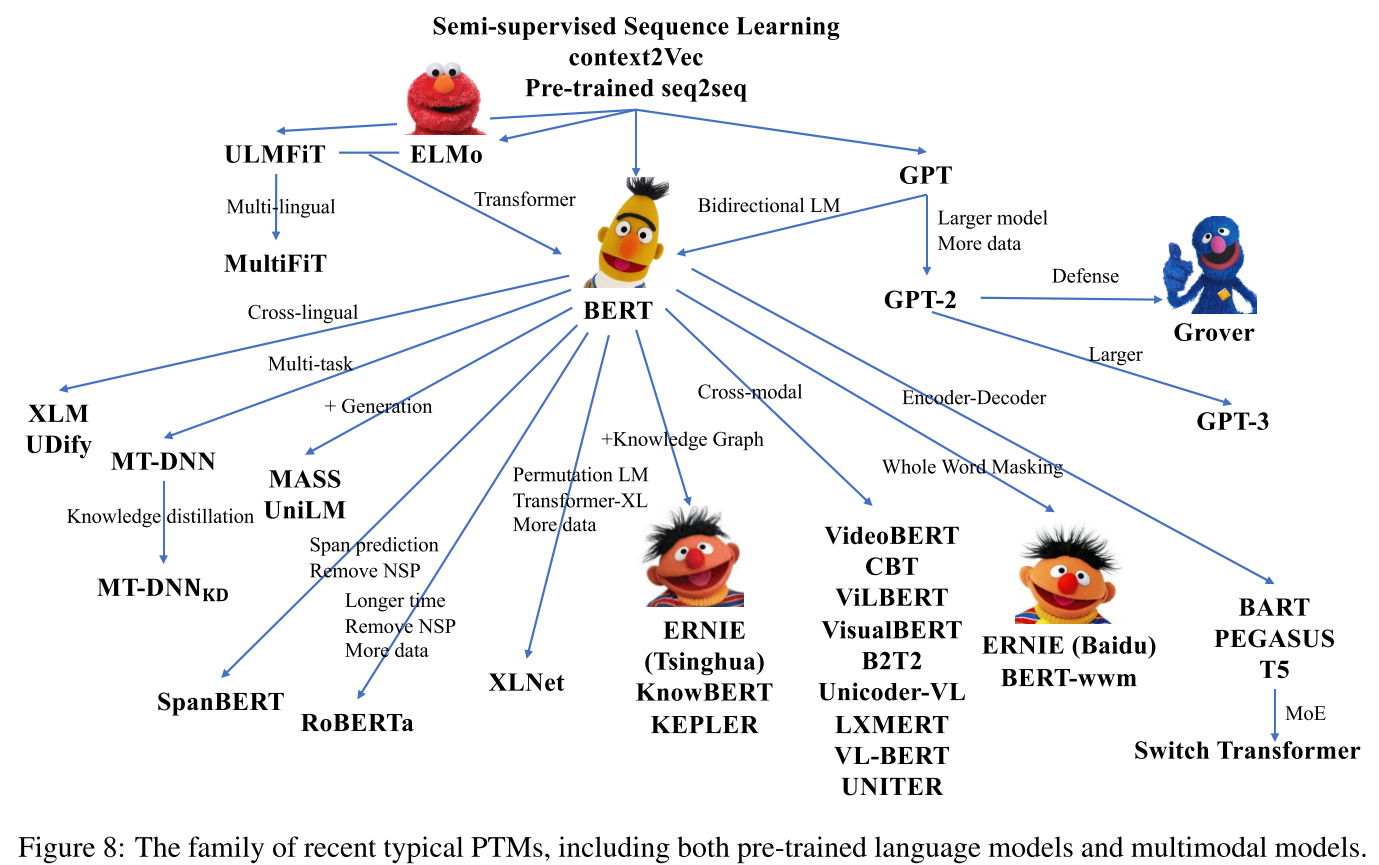
Transformer家族的四大优化方向:
- Some work improves the model architectures and explores novel pre- training tasks, such as XLNet (Yang et al., 2019), UniLM (Dong et al., 2019), MASS (Song et al., 2019), SpanBERT (Joshi et al., 2020) and ELEC- TRA (Clark et al., 2020).
- Besides, incorporating rich data sources is also an important direction, such as utilizing multilingual corpora, knowledge graphs, and images.
- Since the model scale is a crucial success factor of PTMs, researchers also explore to build larger models to reach over hundreds of billions of parameters, such as the series of GPT (Radford et al., 2019; Brown et al., 2020), Switch Transformer (Fedus et al., 2021),
- mean- while conduct computational efficiency optimization for training PTMs (Shoeybi et al., 2019; Ra- jbhandari et al., 2020; Ren et al., 2021).
4 Designing Effective Architectures
two motivations
- 统一NLU和NLG任务
- 从人类cognitive science角度切入
4.1 Unified Sequence Modeling
NLP的三类versatile downstream tasks and applications:
- Natural language understanding: grammatical analysis, syntactic analysis, word/sentence/paragraph classification, ques- tion answering, factual/commonsense knowl- edge inference and etc
- Open-ended language generation: includes dialog generation, story generation, data-to- text generation and etc.
- Non-open-ended language generation: includes machine translation, abstract summarizing, blank filling and etc.
understanding tasks 可以转换为 generation tasks (Schick and Schütze, 2020)。同时生成式的GPT在一些理解类任务上也可以达到甚至超过BERT的效果,因此The boundary between understanding and generation is vague. 基于此观察有如下一些研究方向:
- Combining Autoregressive and Autoencoding Modeling: 就是把GPT的单向生成和BERT的双向理解结合起来, 先驱就是XLNet
- permutated language modeling: XLNet (Yang et al., 2019), MPNet (Song et al., 2020)
- Multi-task training: UniLM (Dong et al., 2019)
- Mask上面做文章: GLM (Du et al., 2021), fill in blanks with variable lengths
- Applying Generalized Encoder-Decoder: 为了生成可变长的目标序列, 采用encoder-decoder architectures
- MASS (Song et al.,2019): introduces the masked-prediction strategy into the encoder-decoder structure.
- T5 (Raffel et al., 2020), : masking a variable-length of span in text with only one mask token and asks the decoder to recover the whole masked sequence.
- BART (Lewis et al., 2020a): corrupting the source sequence with multiple operations such as truncation, deletion, re- placement, shuffling, and masking, instead of mere masking.
Encoder-Decoder架构导致参数更大, 虽然可以通过参数共享减轻, 但效率仍堪忧. Seq2seq的结构在NLU任务上表现不好,低于RoBERTa和GLM

4.2 Cognitive-Inspired Architectures
Transformer的注意力机制利用了人的视觉感知, 但是对于人的decision making, logical reasoning, counterfactual reasoning and working memory (Baddeley, 1992) 没有很好的模拟. 因此就有基于cognitive science的改进方向
- Maintainable Working Memory: 人的注意力机制和Transformer还是不一样的, 人的注意力机制没有Transformer那么long-range, 而是维护一个working memory(Baddeley, 1992; Brown, 1958; Barrouillet et al., 2004; Wharton et al., 1994), 负责记忆, 重组和选择性遗忘, 也就是LSTM所希望达到的目的.
- Transformer-XL (Dai et al., 2019) : introduce segment-level recurrence and relative positional encoding
- CogQA (Ding et al., 2019): maintain a cognitive graph in the multi-hop reading, the System 1 based on PTMs and the System 2 based on GNNs to model the cognitive graph for multi-hop understanding.
- CogLTX (Ding et al., 2020): leverages a MemRecall language model to select sen- tences that should be maintained in the working memory and another model for answering or clas- sificatio
- Sustainable Long-Term Memory: GPT-3 (Brown et al., 2020)表明Transformer有记忆能力, 那么就有动力去进一步挖掘Transformer的记忆能力. Lample et al. (2019)表示feed-forward networks in Transformers is equivalent to memory networks. 但记忆能力有限.
- REALM (Guu et al., 2020) : explore how to construct a sustainable external memory for Transformers. tensorize the whole Wikipedia sentence by sentence, and retrieve relevant sentences as context for masked pre-training.
- RAG (Lewis et al., 2020b) extends the masked pre-training to autoregressive generation, which could be better than extractive question answering.
- (Vergaet al., 2020; Févry et al., 2020) propose to tensorize entities and triples in existing knowledge bases, replace entity tokens’ embedding in an internal Transformer layer with the embedding from outer memory networks.
- (Dhingra et al., 2020; Sun et al., 2021) maintain a virtual knowledge from scratch, and propose a differentiable reasoning training objective over it.
4.3 其他 More Variants of Existing PTMs
focus on optimizing BERT’s architecture to boost language models’ performance on natural language understanding.
- improving the masking strategy: 可以视为一种数据增强
- Span- BERT (Joshi et al., 2020): masking a continuous random-length span of tokens with a span boundary objective (SBO) could improve BERT’s performance
- ERNIE (Sun et al., 2019b,c): entity masking
- NEZHA (Wei et al., 2019)
- Whole Word Masking (Cui et al., 2019)
- change masked-prediction objective to GAN: ELECTRA (Clark et al., 2020) transform MLM to a replace token detection (RTD) objective, in which a generator will replace tokens in original sequences and a discriminator will predict whether a token is replaced.
5 Utilizing Multi-Source Data
5.1 多语言 Multilingual Pre-Training Language
- Multilingual masked language modeling (MMLM): multilingual BERT (mBERT) released by Devlin et al. (2019) is pre- trained with the MMLM task using non-parallel multilingual Wikipedia corpora in 104 languages.
- Translation language modeling (TLM) : MMLM task 无法利用 parallel corpora. 因此有XLM (Lample and Conneau, 2019) leverages bilingual sentence pairs to perform the translation language modeling (TLM) task.
- Unicoder (Huang et al., 2019a): Cross-lingual word recovery (CLWR), Cross-lingual paraphrase classification (CLPC)
- Generative models for multilingual PTMs: MASS (Song et al., 2019) extends MLM to language genera- tion.
- mBART (Liu et al., 2020c) extends DAE to support multiple languages by adding special symbols.
5.2 多模态 Multimodal Pre-Training
Modalities can all be classified as vision and language (V&L),
- ViLBERT (Lu et al., 2019) is a model to learn task-agnostic joint representations of images and languages. two streams of input, by preprocessing textual and visual information separately.
- LXMERT (Tan and Bansal, 2019) has similar architecture compared to Vil- BERT but uses more pre-training tasks
- VisualBERT (Li et al., 2019), on the other side, extends the BERT architecture at the minimum. The Transformer layers of VisualBERT implicitly align elements in the input text and image regions.
- Unicoder-VL (Li et al., 2020a) moves the offsite visual detector in VisualBERT into an end-to-end version: It designs the image token for Transformers as the sum of the bounding box and object label features.
- VL-BERT(Su et al., 2020) also uses a similar architecture to VisualBERT. each input element is either a token from the input sentence or a region-of-interest (RoI) from the input image.
- UNITER (Chen et al., 2020e) learns unified representations between the two modali- ties.
- DALLE (Ramesh et al., 2021) : A bigger step towards conditional zero-shot image generation: transformer-based text-to-image zero- shot pre-trained model with around 10 billiion pa- rameters.
- CLIP (Radford et al., 2021) and Wen-Lan (Huo et al., 2021) explore enlarging web-scale data for V&L pre-training with big success. Com-
5.3 Knowledge-Enhanced Pre-Training
PTMs 可以从大量语料中中提取统计信息. 同时外部知识(such as knowledge graphs, domain- specific data and extra annotations of pre-training data) 可以作为很好的统计先验.
6 Improving Computational Efficiency
6.1 Sstem-Level Optimization
系统层的优化是 model-agnostic and do not change underlying learning algorithms.
- 单机优化:
- half-precision floating-point format (FP16), may fail because of the floating-point truncation and overflow
- mixed- precision training methods: which preserve some critical weights in FP32 to avoid the floating-point overflow and use dynamic loss scaling operations to get rid of the floating-point truncation.
- gradient checkpointing methods(Rasley et al., 2020) have been used to save memory by storing only a part of the activation states after forward pass.
- 如果模型参数太大无法塞入显存, store model parameters and activation states with the CPU memory, ZeRO-Offload (Ren et al., 2021) design delicate strategies to schedule the swap between the CPU memory and the GPU memory so that memory swap and device computation can be over- lapped as much as possible.
- 多机优化
数据并行 Data parallelism (Li et al., 2020d),
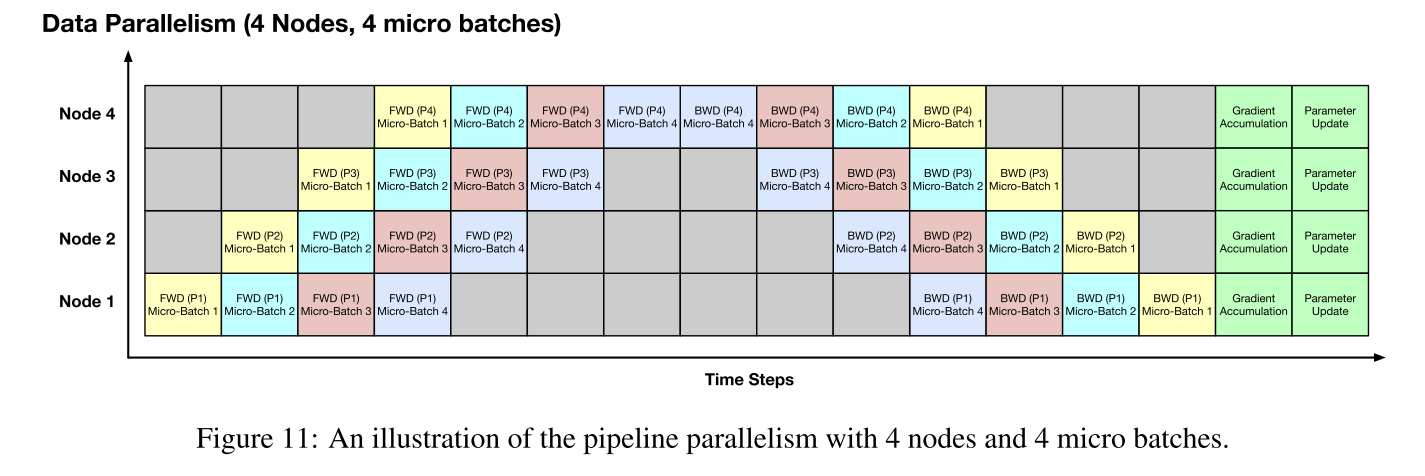
模型并行, Model parallelism: Megatron- LM (Shoeybi et al., 2019) splits self-attention heads as well as feed-forward layers into differ- ent GPUs
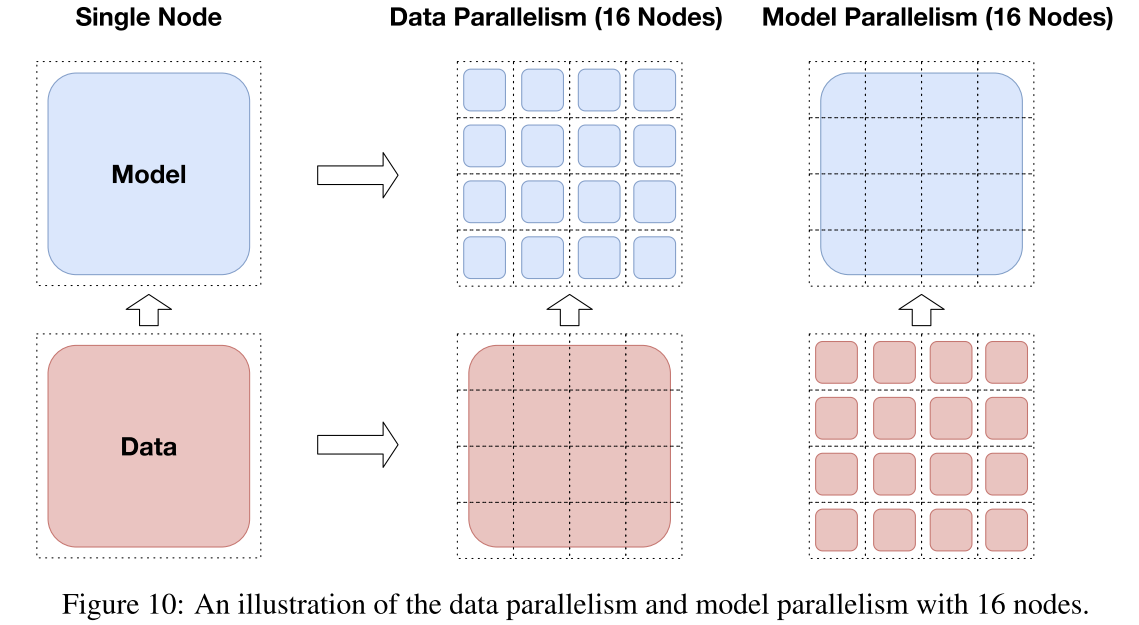
Model pipeline parallelism: partitions a deep neural network into multiple lay- ers and then puts different layers onto different nodes.
- GPipe (Huang et al., 2019b) which can send smaller parts of samples within a mini-batch to different nodes
- TeraPipe (Li et al., 2021) which can apply token-level pipeline mechanisms for Transformer-based models to make each token in a sequence be processed by different nodes.
6.2 Efficient Pre-Training
- 训练方法优化:改进BERT低效的mask机制
- selectively mask tokens based on their importance (Gu et al., 2020) or gra- dients (Chen et al., 2020b) in back-propagation to speed up model training.
- ELECTRA需要识别所有token所以效率更高
- warmup strategy
- different layers can share similar self-attention patterns, 先训练浅层的神经网络, 再复制到更深的网络中
- Some layers can also be dropped during training to reduce the complexity of back-propagation and weight update (Zhang and He, 2020)
- 对不同层使用不同学习率
- 模型结构优化
- 减小模型复杂度,设计low-rank kernels to theoretically approximate the original attention weights and result in linear complexity
- 在attention mechanisms中引入稀疏性,by limiting the view of each token to a fixed size and separating tokens into several chunks so that the computation of attention weights takes place in every single chunk rather than a complete sequence
- Switch Transformers使用的Mix-of-experts to each layer of Transformers
6.3 模型压缩
- 参数共享 Parameter Sharing: ALBERT (Lan et al., 2019) uses factorized embedding parameterization and cross-layer parameter sharing
- 模型剪枝 Model Pruning
- 知识蒸馏 Knowledge Distillation: DistillBERT (Sanh et al., 2019), TinyBERT (Jiao et al., 2019), BERT- PKD (Sun et al., 2019a) and MiniLM (Wang et al., 2020d).
- Model Quantization: Q8BERT (Zafrir et al., 2019), Q-BERT (Shen et al., 2020a), Ternary- BERT (Zhang et al., 2020b) applies
7.1 Knowledge of PTMs
知识分为linguistic knowledge and world knowledge.,
Linguistic Knowledge
- Representation Probing, 通过额外的线性层在下游任务探测Representation 中是否含有语言知识
- Representation Analysis:Use the hidden representations of PTMs to compute some statistics such as distances or similarities, 如 BERT visualization
- Attention analysis:同上
- Generation Analysis:预测单词或句子的分布
- construct analysis tasks based on generation: Perturbed Masking (Wu et al., 2020) recovers syntactic trees from PTMs without any extra parameter and the structure given by PTMs are competitive with a human-designed dependency schema in some downstream tasks.
在11个 linguistic tasks上的结果表明PTMs可以学习到tokens, chunks, and pairwise relations. 通过设计新的任务可以发现PTM编码了syntactic, semantic, local, and long- range information。
World Knowledge
- commonsense knowledge: Davison et al. (2019) propose to first transform relational triples into masked sen- tences and then rank these sentences according to the mutual information given by PTMs. In the ex- periments, the PTM-based extraction method with- out further training even generalizes better than current supervised approaches.
- factual knowledge: Petroni et al. (2019) propose to formulate the relational knowledge generation as the completion of fill-in-the-blank statements.
- LPAQA (Jiang et al., 2020b) search better statements/prompts through mining- based and paraphrasing-based methods.
- Auto - Prompt (Shin et al., 2020) proposes to train discrete prompts for knowledge probing.
- In P-tuning (Liu et al., 2021b), the authors discover that the bet- ter prompts lie in continuous embedding space, rather than discrete space.
7.2 Robustness of PTMs
用Adversarial attacks检验模型鲁棒性,
- PTMs can be easily fooled by synonym replacement (Jin et al., 2020; Zang et al., 2020).
- Irrelevant artifacts such as form words can mislead the PTMs into making wrong predic- tions (Niven and Kao, 2019; Wallace et al., 2019a).
如何生成对抗样本
- utilize the model prediction, prediction probabilities, and model gradients of the models, 但难以保证质量
- human-in-the-loop methods (Wallace et al., 2019b; Nie et al., 2020) generate more natural, valid, and diverse adversarial examples。
7.3 Structural Sparsity of PTMs
- The multi-head attention structures are redundant in the tasks of machine translation (Michel et al., 2019), abstractive summarization (Baan et al., 2019), and language understanding (Kovaleva et al., 2019). 部分研究移除head反而得到更好的表现,一些head的注意力pattern也是相似的。
- Sparsity of parameters:
- Gordon et al. (2020) show low levels of pruning (30-40%) do not affect pre-training loss or the performance on downstream tasks at all.
- Prasanna et al. (2020) validate the lottery ticket hypothesis on PTMs and find that it is possible to find sub-networks achieving per- formance that is comparable with that of the full model.
7.4 Theoretical Analysis of PTMs
Erhan et al. (2010) propose two hypotheses
- better optimization:更接近全局最优
- better regularization:更好的泛化能力
Saunshi et al. (2019) conduct a theoretical analysis of contrastive unsupervised representation learning. they prove that the loss of contrastive learning is the upper bound of the downstream loss.
8 Future Directions
8.1 Architectures and Pre-Training Methods
- New Architectures
- New Pre-Training Tasks
- Beyond Fine-Tuning:An improved solution is to fix the original parameters of PTMs and add small fine-tunable adaption modules for specific tasks.
- Reliability
8.2 Multilingual and Multimodal Pre-Training
- More Modalities: image, text, video and audio
- More Insightful Interpretation: why bridging vision and language works
- More Downstream Applications: 现有的image-text retrieval, image-to-text generation, text-to-image generation 等并不是现实迫切需要的应用.
- Transfer Learning.
8.3 Computational Efficiency
- Data Movement: 设备通信瓶颈
- Parallelism Strategies 设计自动化
- Large-Scale Training